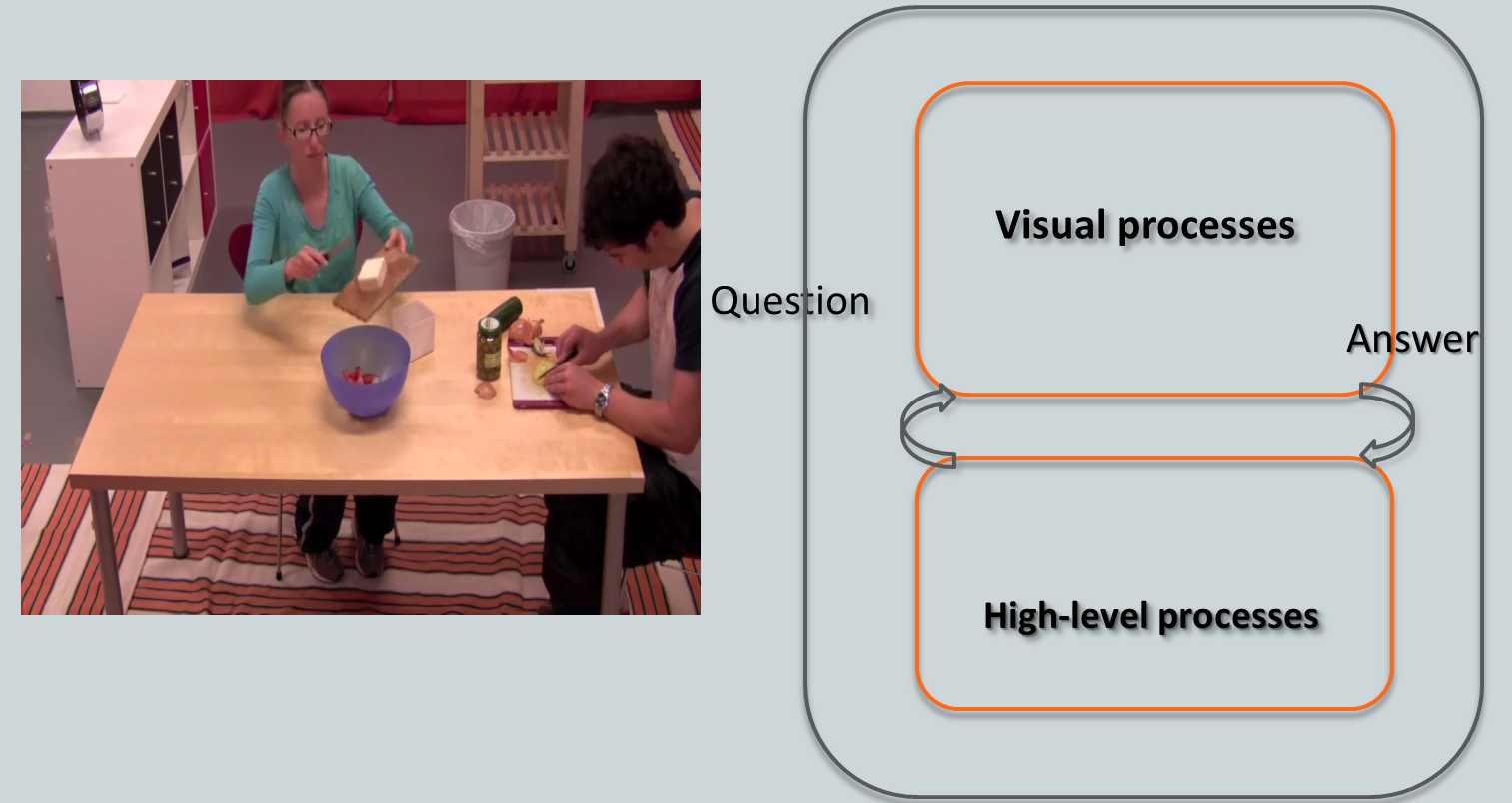
Learning for action-based scene understanding
Cornelia Fermüller and Michael Maynord
Advanced Methods and Learning in Computer Vision, January, 2022
Chapter
Abstract
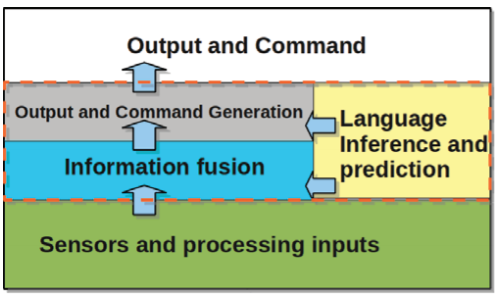
In this chapter we outline an action-centric framework which spans multiple time scales and levels of
abstraction, producing both action and scene interpretations constrained towards action consistency.
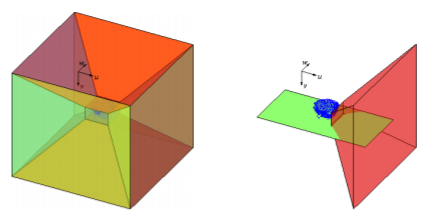
At the lower level of the visual hierarchy we detail affordances – object characteristics which afford themselves to different actions.
At mid-levels we model individual actions, and at higher levels we model activities through leveraging knowledge and
longer term temporal relations.
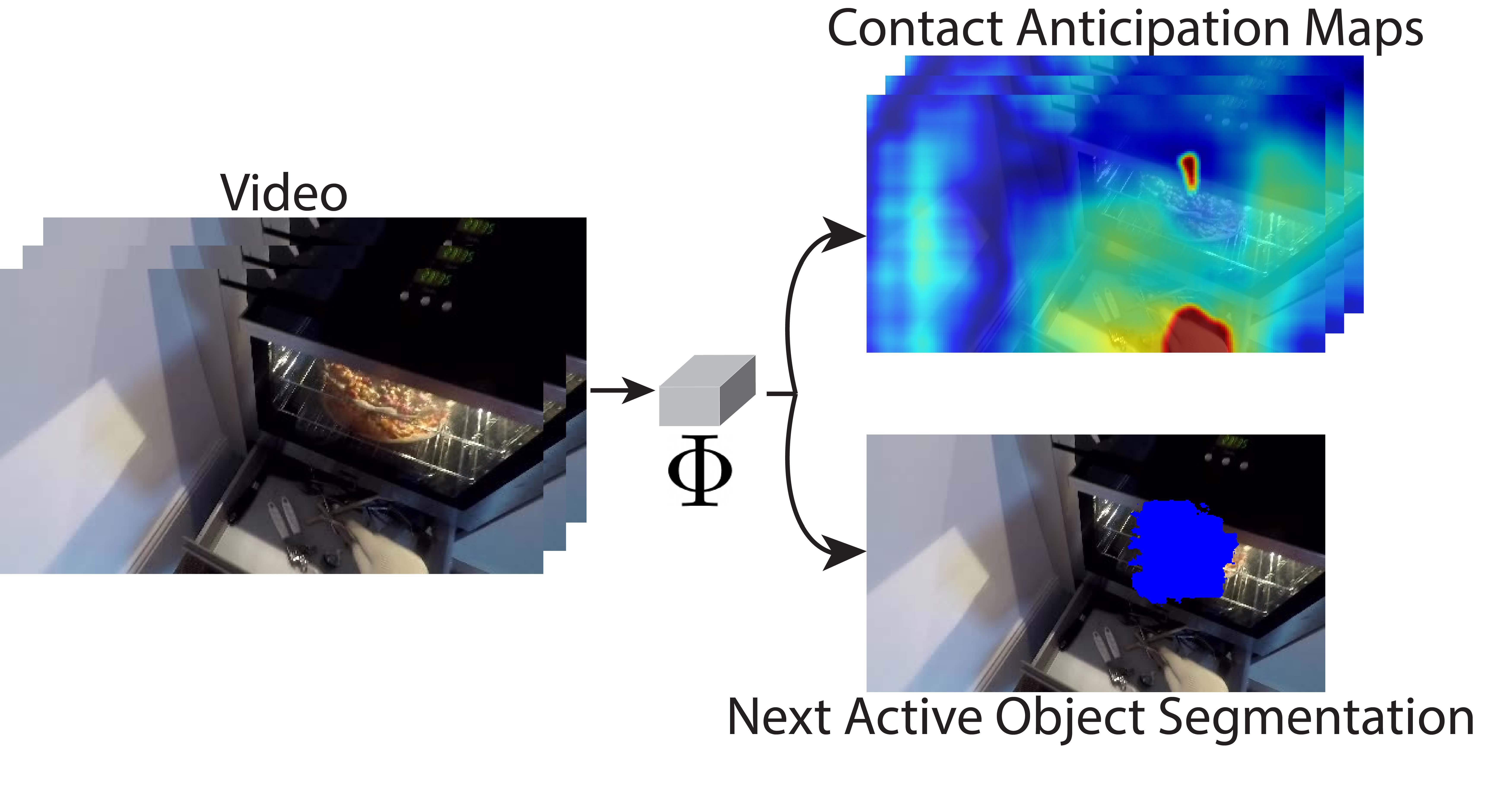
Forecasting Action through Contact Representations from First Person Video
Eadom Dessalene, Chinmaya Devaraj, Michael Maynord, Cornelia Fermüller, and Yiannis Aloimonos
IEEE Transactions on Pattern Analysis and Machine Intelligence, January, 2021.
Paper
Abstract
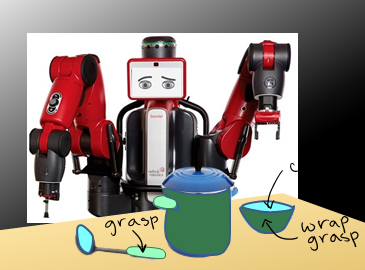
Human actions involving hand manipulations are structured according to the making and breaking of hand-object contact,
and human visual understanding of action is reliant on anticipation of contact as is demonstrated by pioneering work in cognitive
science. Taking inspiration from this, we introduce representations and models centered on contact, which we then use in action
prediction and anticipation. We annotate a subset of the EPIC Kitchens dataset to include time-to-contact between hands and objects,
as well as segmentations of hands and objects. Using these annotations we train the Anticipation Module, a module producing Contact
Anticipation Maps and Next Active Object Segmentations - novel low-level representations providing temporal and spatial
characteristics of anticipated near future action. On top of the Anticipation Module we apply Egocentric Object Manipulation Graphs
(Ego-OMG), a framework for action anticipation and prediction. Ego-OMG models longer term temporal semantic relations through the
use of a graph modeling transitions between contact delineated action states. Use of the Anticipation Module within Ego-OMG
produces state-of-the-art results, achieving 1 st and 2 nd place on the unseen and seen test sets, respectively, of the EPIC Kitchens
Action Anticipation Challenge, and achieving state-of-the-art results on the tasks of action anticipation and action prediction over EPIC
Kitchens. We perform ablation studies over characteristics of the Anticipation Module to evaluate their utility.
Computer Vision and Natural Language Processing: Recent approaches in Multimedia and Robotics
Peratham Wiriyathammabhum, Douglas Summers-Stay, Cornelia Fermüller, and Yiannis Aloimonos
ACM Computing Surveys (CSUR) 49 (4), 71, 2017.
Paper
Abstract
Integrating computer vision and natural language processing is a novel interdisciplinary field that has received a lot of attention recently. In this survey, we provide a comprehensive introduction of the integration of computer vision and natural
language processing in multimedia and robotics applications with more than 200 key references. The tasks that we survey include visual attributes, image captioning, video captioning, visual question answering, visual retrieval, human-robot interaction,
robotic actions, and robot navigation. We also emphasize strategies to integrate computer vision and natural language processing models as a unified theme of distributional semantics. We make an analog of distributional semantics in computer
vision and natural language processing as image embedding and word embedding, respectively. We also present a unified view for the field and propose possible future directions.
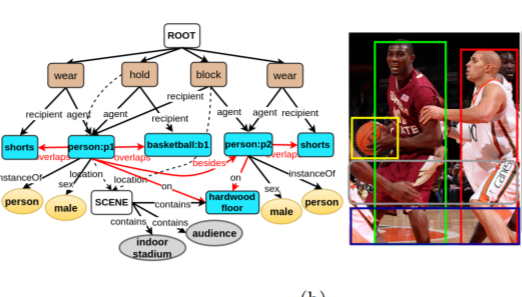
Image Understanding Using Vision and Reasoning through Scene Description Graphs
Somak Aditya, Yezhou Yang, Chitta Baral, Yiannis Aloimonos, and Cornelia Fermüller
Computer Vision and Image Understanding , Dec. 2017.
Paper
Abstract
Webpage
Two of the fundamental tasks in image understanding using text are caption generation and visual question answering. This work presents an intermediate knowledge structure that can be used for both tasks to obtain increased interpretability. We
call this knowledge structure Scene Description Graph (SDG), as it is a directed labeled graph, representing objects, actions, regions, as well as their attributes, along with inferred concepts and semantic (from KM-Ontology), ontological (i.e.
superclass, hasProperty), and spatial relations. Thereby a general architecture is proposed in which a system can represent both the content and underlying concepts of an image using an SDG. The architecture is implemented using generic visual
recognition techniques and commonsense reasoning to extract graphs from images. The utility of the generated SDGs is demonstrated in the applications of image captioning, image retrieval, and through examples in visual question answering. The
experiments in this work show that the extracted graphs capture syntactic and semantic content of images with reasonable accuracy.
DeepIU: An Architecture for Image Understanding
Somak Aditya, Chitta Baral, Yezhou Yang, Yiannis Aloimonos, and Cornelia Fermüller
Advances in Cognitive Systems 4, 2016.
Paper
Abstract
Image Understanding is fundamental to systems that need to extract contents and infer concepts from images. In this paper, we develop an architecture for understanding images, through which a system can recognize the content and the underlying
concepts of an image and, reason and answer questions about both using a visual module, a reasoning module, and a commonsense knowledge base. In this architecture, visual data combines with background knowledge and; iterates through visual and
reasoning modules to answer questions about an image or to generate a textual description of an image. We first provide motivations of such a Deep Image Understanding architecture and then, we describe the necessary components it should include.
We also introduce our own preliminary implementation of this architecture and empirically show how this more generic implementation compares with a recent end-to-end Neural approach on specific applications. We address the knowledge-representation
challenge in such an architecture by representing an image using a directed labeled graph (called Scene Description Graph). Our implementation uses generic visual recognition techniques and commonsense reasoning1 to extract such graphs from
images. Our experiments show that the extracted graphs capture the syntactic and semantic content of an image with reasonable accuracy.
The cognitive dialogue: A new model for vision implementing common sense reasoning
Yiannis Aloimonos and Cornelia Fermüller
Image and Vision Computing, 34, 42-44, 2015.
Paper
Abstract
We propose a new model for vision, where vision is part of an intelligent system that reasons. To achieve this we need to integrate perceptual processing with computational reasoning and linguistics. In this paper we present the basics of this
formalism.
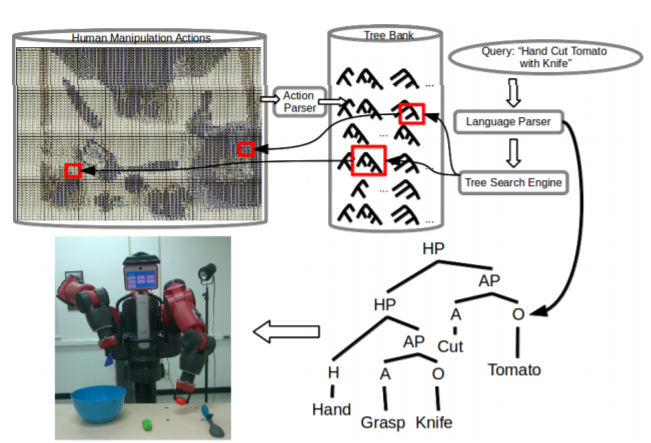
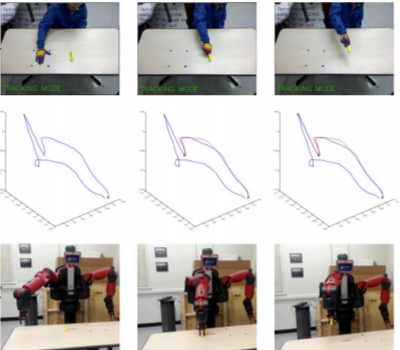
Robot Learning Manipulation Action Plans by "Watching" Unconstrained Videos From the World Wide Web
Yezhou Yang, Yi Li, Cornelia Fermüller, and Yiannis Aloimonos.
The Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015.
Paper
Abstract
In order to advance action generation and creation in robots
beyond simple learned schemas we need computational tools
that allow us to automatically interpret and represent human
actions. This paper presents a system that learns manipulation
action plans by processing unconstrained videos from
the World Wide Web. Its goal is to robustly generate the sequence
of atomic actions of seen longer actions in video in
order to acquire knowledge for robots. The lower level of the
system consists of two convolutional neural network (CNN)
based recognition modules, one for classifying the hand grasp
type and the other for object recognition. The higher level
is a probabilistic manipulation action grammar based parsing
module that aims at generating visual sentences for robot
manipulation. Experiments conducted on a publicly available
unconstrained video dataset show that the system is able
to learn manipulation actions by “watching” unconstrained
videos with high accuracy.
Learning the Semantics of Manipulation Action
Yezhou Yang, Cornelia Fermüller, Yiannis Aloimonos, and Eren Erdal Aksoy.
The 53rd Annual Meeting of the Association for Computational Linguistics (ACL) . 2015.
Paper
Abstract
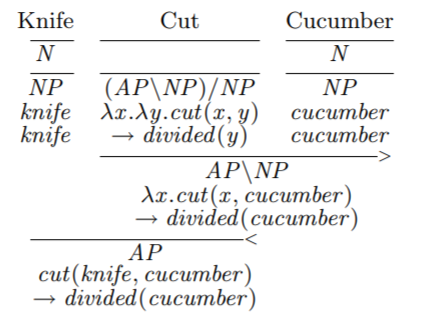
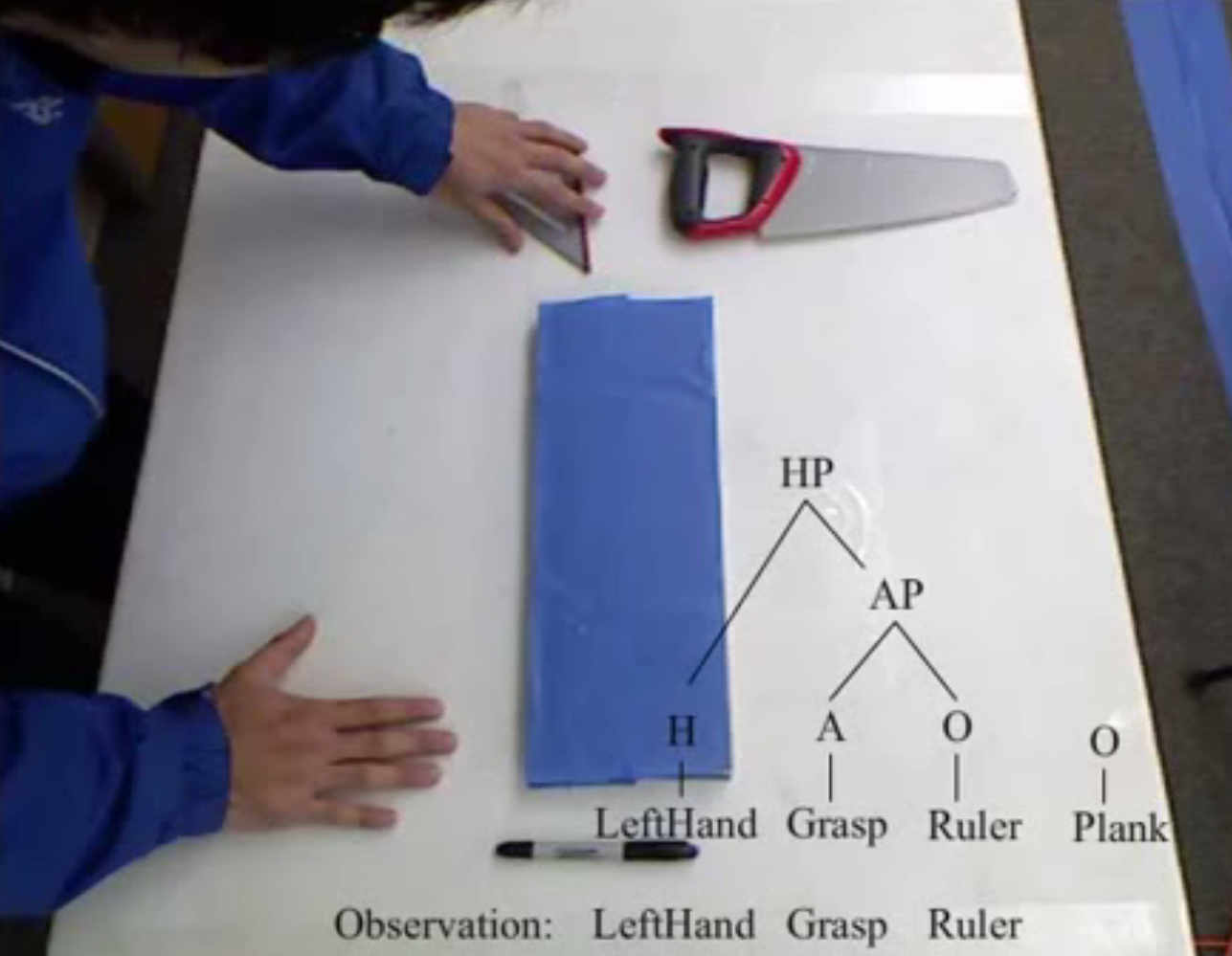
In this paper we present a formal computational framework for modeling manipulation actions. The introduced formalism leads to semantics of manipulation action and has applications to both observing and understanding human manipulation actions
as well as executing them with a robotic mechanism (e.g. a humanoid robot). It is based on a Combinatory Categorial Grammar. The goal of the introduced framework is to: (1) represent manipulation actions with both syntax and semantic parts,
where the semantic part employs λ-calculus; (2) enable a probabilistic semantic parsing schema to learn the lambda-calculus representation of manipulation action from an annotated action corpus of videos; (3) use (1) and (2) to develop a system
that visually observes manipulation actions and understands their meaning while it can reason beyond observations using propositional logic and axiom schemata. The experiments conducted on a public available large manipulation action dataset
validate the theoretical framework and our implementation..
Visual common-sense for scene understanding using perception, semantic parsing and reasoning
Somak Aditya, Yezhou Yang, Chitta Baral, Cornelia Fermüller, and Yiannis Aloimonos
The Twelfth International Symposium on Logical Formalization on Commonsense Reasoning, 2015.
Paper
Abstract
In this paper we explore the use of visual commonsense knowledge and other kinds of knowledge (such as domain knowledge, background knowledge, linguistic knowledge) for scene understanding. In particular, we combine visual processing with techniques
from natural language understanding (especially semantic parsing), common-sense reasoning and knowledge representation and reasoning to improve visual perception to reason about finer aspects of activities.
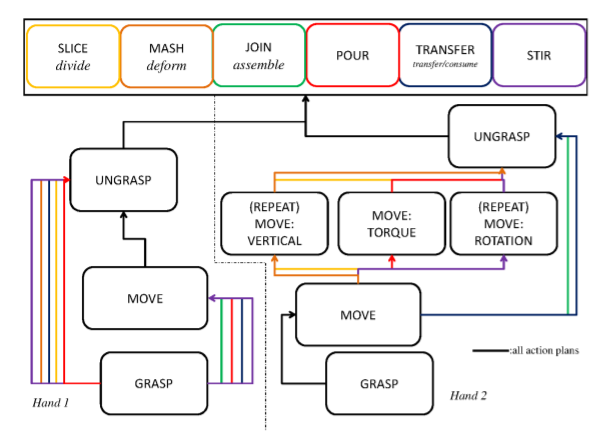
A Cognitive System for Understanding Human Manipulation Actions.
Yezhou Yang, Cornelia Fermüller, Yiannis Aloimonos, and Anupam Guha
Advances in Cognitive Systems 3, 67–86, 2014.
Paper
Abstract
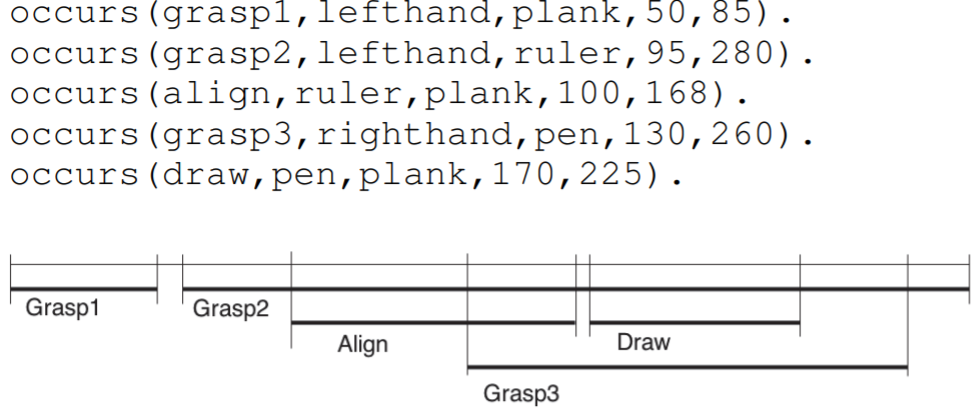
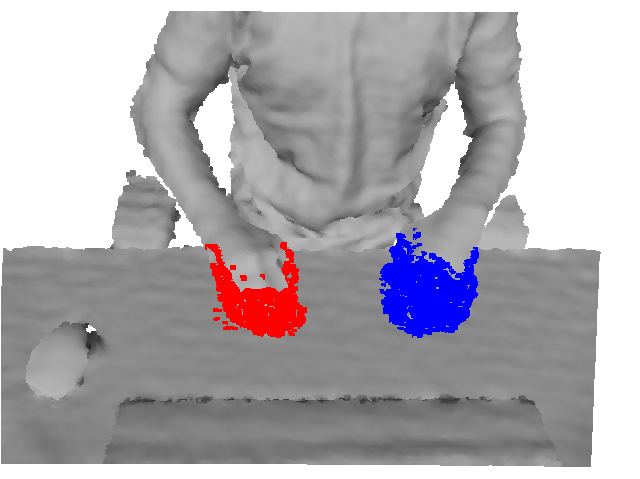
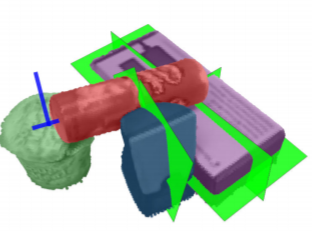
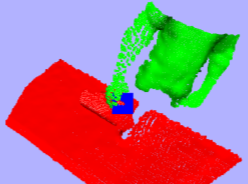
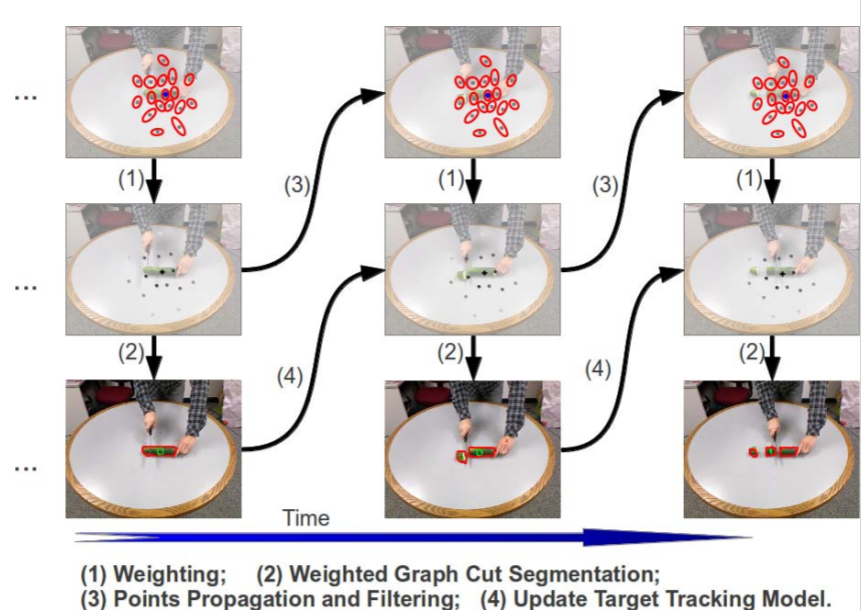
This paper describes the architecture of a cognitive system that interprets human manipulation actions from perceptual information (image and depth data) and that includes interacting modules for perception and reasoning. Our work contributes
to two core problems at the heart of action understanding: (a) the grounding of relevant information about actions in perception (the perception-action integration problem), and (b) the organization of perceptual and high-level symbolic information
for interpreting the actions (the sequencing problem). At the high level, actions are represented with the Manipulation Action Grammar, a context-free grammar that organizes actions as a sequence of sub events. Each sub event is described by
the hand, movements, objects and tools involved, and the relevant information about these factors is obtained from biologicallyinspired perception modules. These modules track the hands and objects, and they recognize the hand grasp, objects
and actions using attention, segmentation, and feature description. Experiments on a new data set of manipulation actions show that our system extracts the relevant visual information and semantic representation. This representation could further
be used by the cognitive agent for reasoning, prediction, and planning.
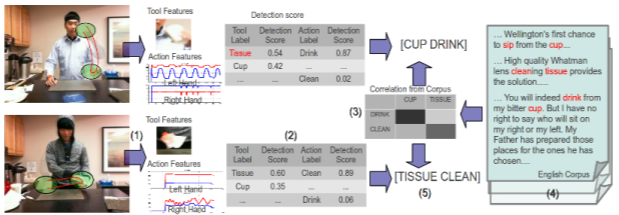
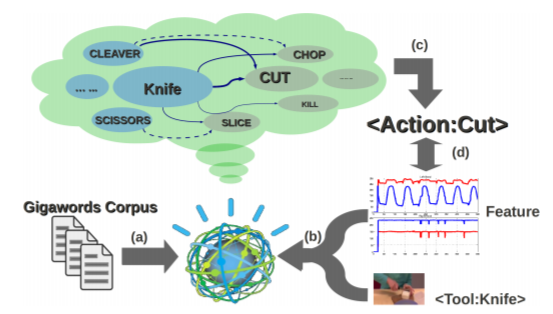
A Corpus-Guided Framework for Robotic Visual Perception.
Yezhou Yang, Ching L. Teo, Hal Daumé III, Cornelia Fermüller, and Yiannis Aloimonos
AAAI Workshop on Language-Action Tools for Cognitive Artificial Agents, 2011
Paper
Abstract
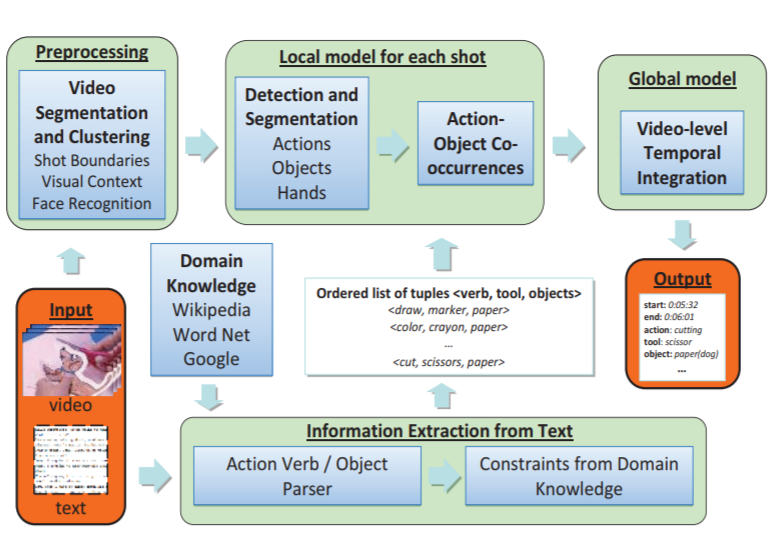
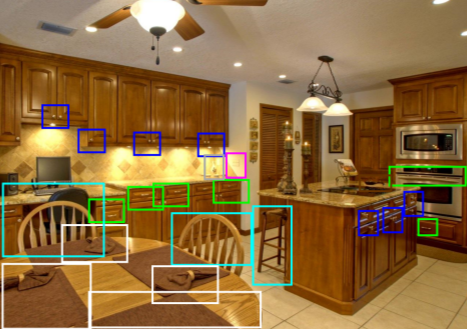
We present a framework that produces sentence-level summarizations of videos containing complex human activities that can be implemented as part of the Robot Perception Control Unit (RPCU). This is done via: 1) detection of pertinent objects in
the scene: tools and direct-objects, 2) predicting actions guided by a large lexical corpus and 3) generating the most likely sentence description of the video given the detections. We pursue an active object detection approach by focusing on
regions of high optical flow. Next, an iterative EM strategy, guided by language, is used to predict the possible actions. Finally, we model the sentence generation process as a HMM optimization problem, combining visual detections and a trained
language model to produce a readable description of the video. Experimental results validate our approach and we discuss the implications of our approach to the RPCU in future applications.
Active scene recognition with vision and language
Xiaodong Yu, Cornelia Fermüller, Ching-Lik Teo, Yezhou Yang, and Yiannis Aloimonos
IEEE Int. Conference on Computer Vision (ICCV), 810-817, 2011.
Paper
Abstract
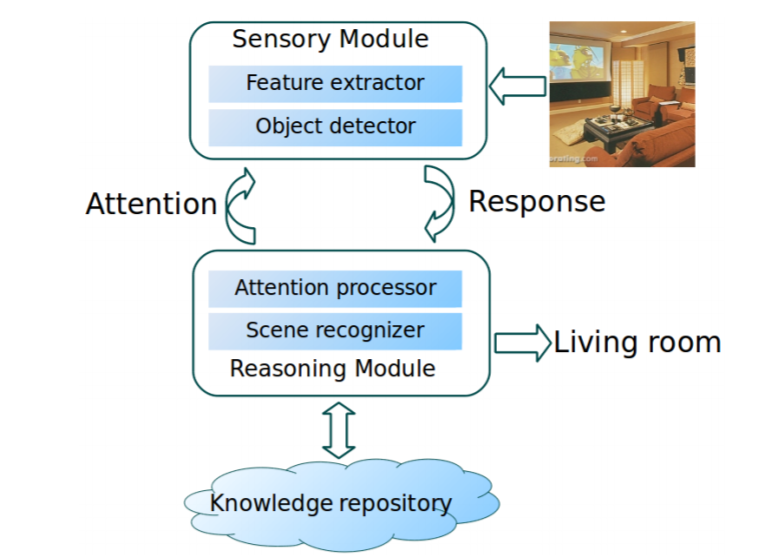
This paper presents a novel approach to utilizing high level knowledge for the problem of scene recognition in an active vision framework, which we call active scene recognition. In traditional approaches, high level knowledge is used in the post-processing
to combine the outputs of the object detectors to achieve better classification performance. In contrast, the proposed approach employs high level knowledge actively by implementing an interaction between a reasoning module and a sensory module
(Figure 1). Following this paradigm, we implemented an active scene recognizer and evaluated it with a dataset of 20 scenes and 100+ objects. We also extended it to the analysis of dynamic scenes for activity recognition with attributes. Experiments
demonstrate the effectiveness of the active paradigm in introducing attention and additional constraints into the sensing process.
Language Models for Semantic Extraction and Filtering in Video Action Recognition
Evelyne Tzoukermann, Jan Neumann, Jana Kosecka, Cornelia Fermüller, Ian Perera, Frank Ferraro, Ben Sapp, Rizwan Chaudhry, Gautam Singh.
The Twenty-Ninth AAAI Conference on Artificial Intelligence, 2011.
Paper
Abstract
The paper addresses the following issues: (a) how to represent semantic information from natural language so that a vision model can utilize it? (b) how to extract the salient textual information relevant to vision? For a given domain, we present
a new model of semantic extraction that takes into account word relatedness as well as word disambiguation in order to apply to a vision model. We automatically process the text transcripts and perform syntactic analysis to extract dependency
relations. We then perform semantic extraction on the output to filter semantic entities related to actions. The resulting data are used to populate a matrix of co-occurrences utilized by the vision processing modules. Results show that explicitly
modeling the co-occurrence of actions and tools significantly improved performance.