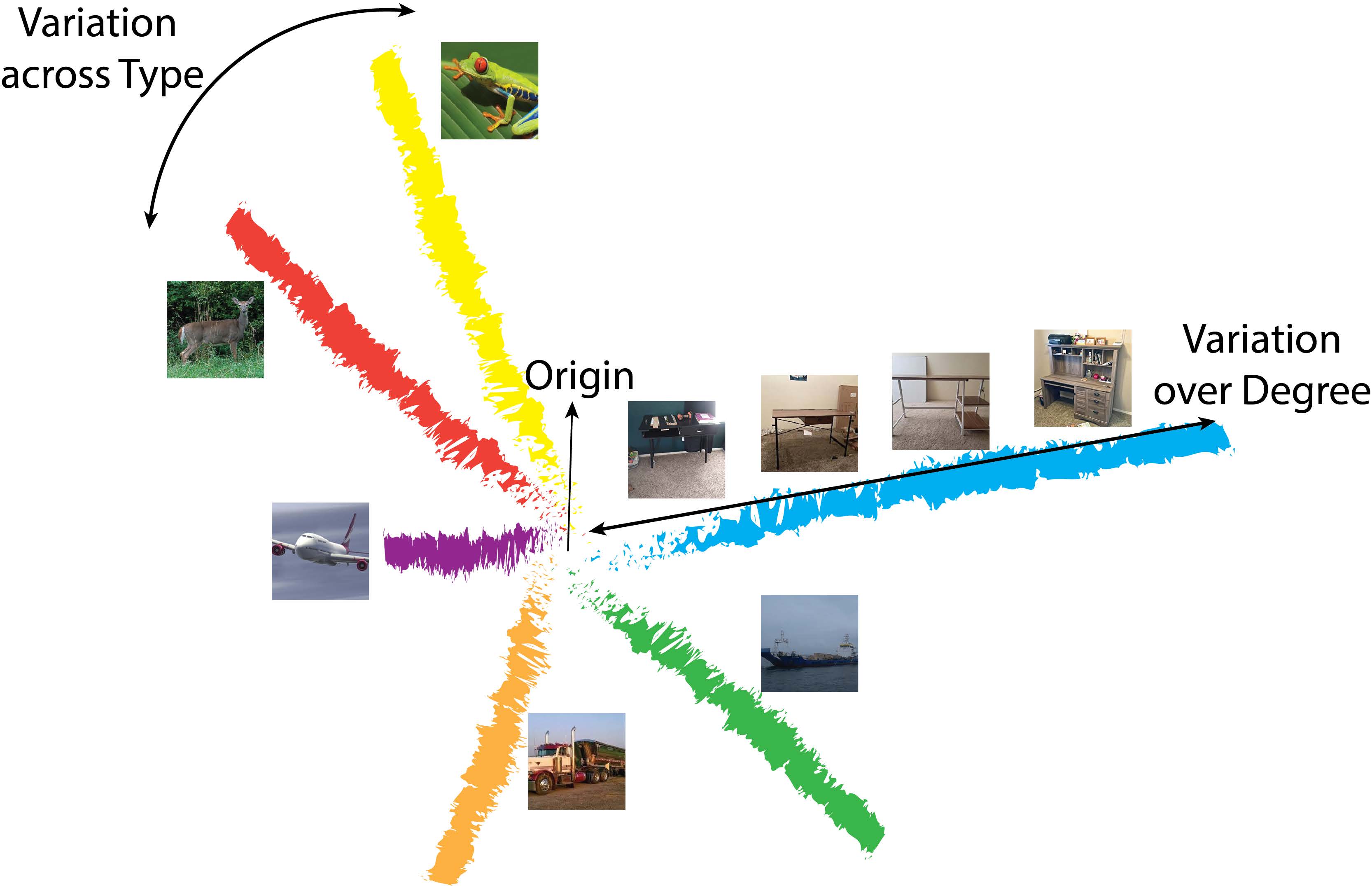
Mid-Vison Feedback
Michael Maynord, Eadom Dessalene, Cornelia Fermüller, and Daniel Dementhon,
International Conference on Learning Representations (ICLR), 2023
The paper introduces
a novel mechanism to modulate visual object classification based on high level categorical
expectations.
Paper
Abstract
Feedback plays a prominent role in biological vision, where perception is modulated
based on agents’ evolving expectations and world model. We introduce
a novel mechanism which modulates perception based on high level categorical
expectations: Mid-Vision Feedback (MVF). MVF associates high level contexts
with linear transformations. When a context is ”expected” its associated linear
transformation is applied over feature vectors in a mid level of a network. The
result is that mid-level network representations are biased towards conformance
with high level expectations, improving overall accuracy and contextual consistency.
Additionally, during training mid-level feature vectors are biased through
introduction of a loss term which increases the distance between feature vectors
associated with different contexts. MVF is agnostic as to the source of contextual
expectations, and can serve as a mechanism for top down integration of symbolic
systems with deep vision architectures. We show the superior performance of
MVF to post-hoc filtering for incorporation of contextual knowledge, and show
superior performance of configurations using predicted context (when no context
is known a priori) over configurations with no context awareness.
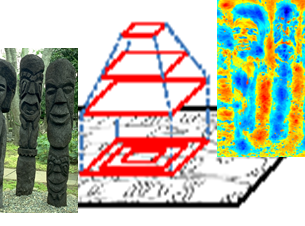
The image torque operator: A new tool for mid-level vision
Morimichi Nishigaki, Cornelia Fermüller, and Daniel Dementhon,
IEEE International Conference on Computer Vision (CVPR), 2012
The Torque is an image processing operator that implements the Gestaltist principle of closure.
This paper demonstrates the Torque for the applications of attention, boundary detection, and segmentation.
Paper
Abstract
Code
Contours are a powerful cue for semantic image understanding. Objects and parts of objects in the image are delineated from their surrounding by closed contours which
make up their boundary. In this paper we introduce a new
bottom-up visual operator to capture the concept of closed
contours, which we call the ’Torque’ operator. Its computation is inspired by the mechanical definition of torque or
moment of force, and applied to image edges. The torque
operator takes as input edges and computes over regions of
different size a measure of how well the edges are aligned
to form a closed, convex contour. We explore fundamental
properties of this measure and demonstrate that it can be
made a useful tool for visual attention, segmentation, and
boundary edge detection by verifying its benefits on these
applications.
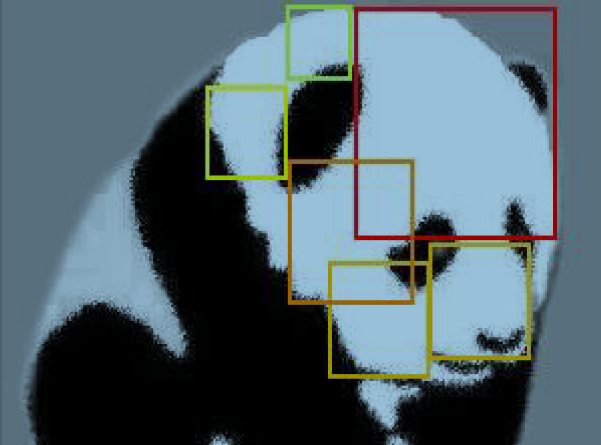
Contour-based recognition
Yong Xu, Yuhui Quan, Zhuming Zhang, Hui Ji, Cornelia Fermüller, Masakatsu Nishigaki, and Daniel Dementhon.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
This paper demonstrates the Torque as a useful tool for object recognition. As it uses contours, it is complimentary to commonly used feature descriptors, such as SIFT.
Paper
Abstract
Contour is an important cue for object recognition. In this paper, built upon the concept of torque in image space, we propose a new contour-related feature to detect and describe local contour information in images. There are two components for
our proposed feature: One is a contour patch detector for detecting image patches with interesting information of object contour, which we call the Maximal/Minimal Torque Patch (MTP) detector. The other is a contour patch descriptor for characterizing
a contour patch by sampling the torque values, which we call the Multi-scale Torque (MST) descriptor. Experiments for object recognition on the Caltech-101 dataset showed that the proposed contour feature outperforms other contour-related features
and is on a par with many other types of features. When combing our descriptor with the complementary SIFT descriptor, impressive recognition results are observed.
A Gestaltist approach to contour-based object recognition: Combining bottom-up and top-down cues
Ching L Teo, Cornelia Fermüller, Yiannis Aloimonos
Advances in Computational Intelligence, 309-321, Springer International Publishing, 2015.
The International Journal of Robotics Research
The Torque is used first in a bottom-up way to detect possible objects. Then task-driven, high-level processes modulate the Torque to recognize specific objects.
Paper
Abstract
Project page
This paper proposes a method for detecting generic classes of objects from their representative contours that can be used by a robot with vision to find objects in cluttered environments. The approach uses a mid-level image operator to group edges
into contours which likely correspond to object boundaries. This mid-level operator is used in two ways, bottom-up on simple edges and top-down incorporating object shape information, thus acting as the intermediary between low-level and high-level
information. First, the mid-level operator, called the image torque, is applied to simple edges to extract likely fixation locations of objects. Using the operator’s output, a novel contour-based descriptor is created that extends the shape context
descriptor to include boundary ownership information and accounts for rotation. This descriptor is then used in a multi-scale matching approach to modulate the torque operator towards the target, so it indicates its location and size. Unlike other
approaches that use edges directly to guide the independent edge grouping and matching processes for recognition, both of these steps are effectively combined using the proposed method. We evaluate the performance of our approach using four diverse
datasets containing a variety of object categories in clutter, occlusion and viewpoint changes. Compared with current state-of-the-art approaches, our approach is able to detect the target with fewer false alarms in most object categories. The
performance is further improved when we exploit depth information available from the Kinect RGB-Depth sensor by imposing depth consistency when applying the image torque.
Fast 2d border ownership assignment
Ching Teo, Cornelia Fermüller, Yiannis Aloimonos.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
Local and global features, inspired from psychological studies, are used to learn contour detection and assignment of neighboring foreground and background.
Paper
Abstract
Project page
A method for efficient border ownership assignment in 2D images is proposed. Leveraging on recent advances using Structured Random Forests (SRF) for boundary detection, we impose a novel border ownership structure that detects both boundaries and
border ownership at the same time. Key to this work are features that predict ownership cues from 2D images. To this end, we use several different local cues: shape, spectral properties of boundary patches, and semi-global grouping cues that are
indicative of perceived depth. For shape, we use HoG-like descriptors that encode local curvature (convexity and concavity). For spectral properties, such as extremal edges, we first learn an orthonormal basis spanned by the top K eigenvectors
via PCA over common types of contour tokens. For grouping, we introduce a novel mid-level descriptor that captures patterns near edges and indicates ownership information of the boundary. Experimental results over a subset of the Berkeley Segmentation
Dataset (BSDS) and the NYU Depth V2 dataset show that our method’s performance exceeds current state-of-the-art multi-stage approaches that use more complex features.
Detection and segmentation of 2D curved reflection symmetric structures
Ching Teo, Cornelia Fermüller, Yiannis Aloimonos.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
Curved reflectional symmetries of objects are detected and then used to segment these objects.
Paper
Abstract
Project page
Symmetry, as one of the key components of Gestalt theory, provides an important mid-level cue that serves as input to higher visual processes such as segmentation. In this work, we propose a complete approach that links the detection of curved reflection
symmetries to produce symmetryconstrained segments of structures/regions in real images with clutter. For curved reflection symmetry detection, we leverage on patch-based symmetric features to train a Structured Random Forest classifier that detects
multiscaled curved symmetries in 2D images. Next, using these curved symmetries, we modulate a novel symmetryconstrained foreground-background segmentation by their symmetry scores so that we enforce global symmetrical consistency in the final
segmentation. This is achieved by imposing a pairwise symmetry prior that encourages symmetric pixels to have the same labels over a MRF-based representation of the input image edges, and the final segmentation is obtained via graph-cuts. Experimental
results over four publicly available datasets containing annotated symmetric structures: 1) SYMMAX-300, 2) BSD-Parts, 3) Weizmann Horse (both from) and 4) NY-roads demonstrate the approach’s applicability to different environments with state-of-the-art
performance.
Shadow-Free Segmentation in Still Images Using Local Density Measure
Aleksandrs. Ecins, Cornelia Fermüller, Yiannis Aloimonos. .
International Conference on Computational Photography (ICCP), 2014 .
A figure-ground segmentation algorithm, not affected by shaow is proposed, that specifically has been designed for textured regions
Paper
Abstract
Project page
Over the last decades several approaches were introduced to deal with cast shadows in background subtraction applications. However, very few algorithms exist that address the same problem for still images. In this paper we propose a figure ground
segmentation algorithm to segment objects in still images affected by shadows. Instead of modeling the shadow directly in the segmentation process our approach works actively by first segmenting an object and then testing the resulting boundary
for the presence of shadows and resegmenting again with modified segmentation parameters. In order to get better shadow boundary detection results we introduce a novel image preprocessing technique based on the notion of the image density map.
This map improves the illumination invariance of classical filterbank based texture description methods. We demonstrate that this texture feature improves shadow detection results. The resulting segmentation algorithm achieves good results on
a new figure ground segmentation dataset with challenging illumination conditions.