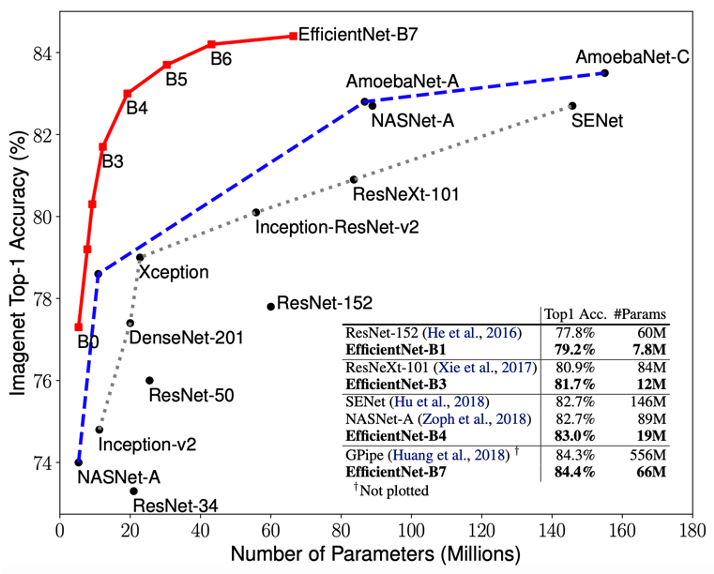
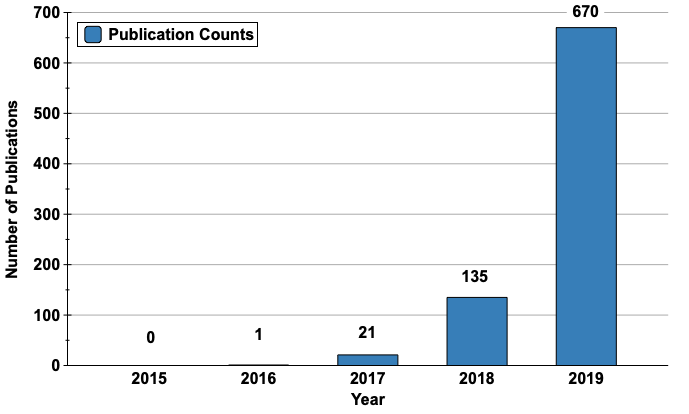
Neural architecture search (NAS) is a hot topic currently. This is because designing new architectures is hard. Jeff Dean, the keynote speaker at the ICML Workshop on Automated Machine Learning (AutoML 2019), emphasized the importance of neural architecture search (NAS) by saying “Tons of organizations in the world have machine learning problems, but only 10s or 100s of thousands of people trained to design such neural network architectures.” A result of this is the trend shown in the left figure: unique DNN architectures found through NAS are progressively outperforming conventional architectures. For example, EfficientNet (Tan et al. 2019) achieves the highest top-1 accuracy on ImageNet (84.4%) using the same number of parameters as the conventional DNN architecture, ResNet. We expect that this trend will continue in the future, and NAS will be applied to various AI problems. This is further suggested by the number of publications on NAS that is already growing exponentially, as shown in the right figure.
Running a NAS algorithm is a computationally demanding process. The common search procedure is as follows: (1) You have a search algorithm (a controller RNN) that recursively predicts the rest of the structure of a unique DNN architecture from a search space with a certain probability. (2) In each iteration, the algorithm trains the predicted structure on a training set, evaluates the accuracy over a test data, and updates the probability. This process is expensive as it contains the training of multiple DNNs over a search, e.g., running the NASNet procedure takes 40k GPU hours (4.56 years on a single GPU). Thus, the organizations that find unique DNN architectures have a strong incentive to keep them as trade secrets.
Our research started with a simple question: Can we steal unique DNN architectures from organizations that either spend a large amount of human resources to hand-craft those architectures or extreme computational resources to run NAS?
Why? Typically, once unique DNN architectures are found by an excessive amount of practitioners’ effort, they are deployed in the cloud by using services such as Google AutoML or AWS SageMaker to reach out to millions of users. However, using cloud-based services make the system running in the cloud vulnerable to remote hardware side-channel attacks such as Flush+Reload [1, 2], which especially has been shown to be effective at stealing sensitive information, such as cryptographic keys. Moreover, Flush+Reload is practical, as the attacker doesn’t require physical proximity to hardware that runs unique DNN architectures or direct query access to the DNN models to train an approximate model. Our intuition was that the leakage from Flush+Reload contains the information details of a unique DNN architecture.
Wait a second, what is Flush+Reload?
Flush+Reload is a cache side-channel attack that exploits a hardware vulnerability. Briefly, the attack uses the timing differences between memory accesses from the cache and from the memory (DRAM). To understand, we need to know how last-level cache works.
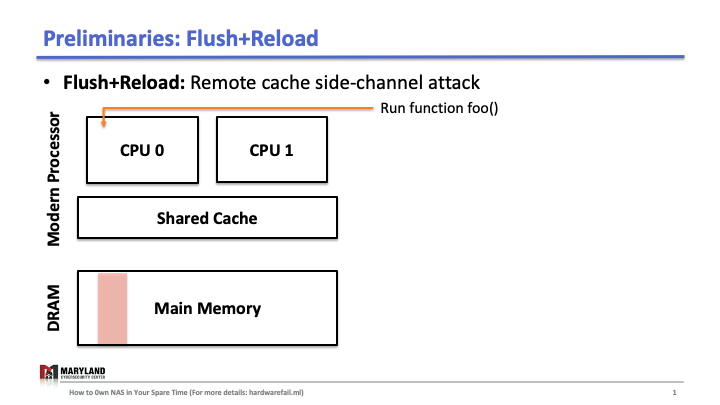
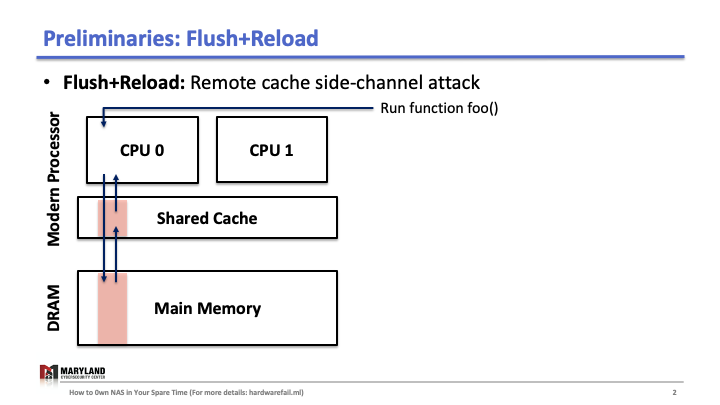
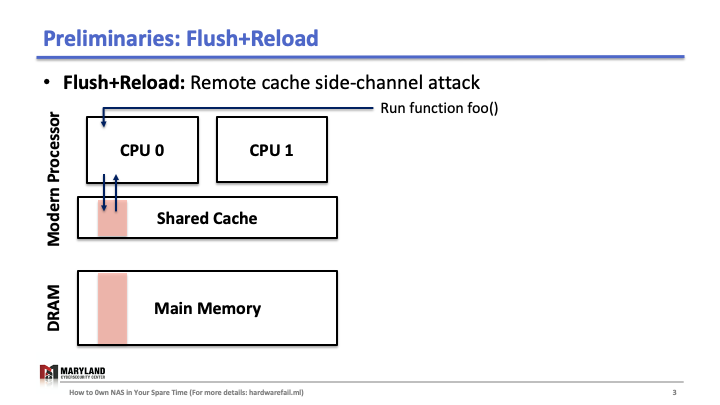
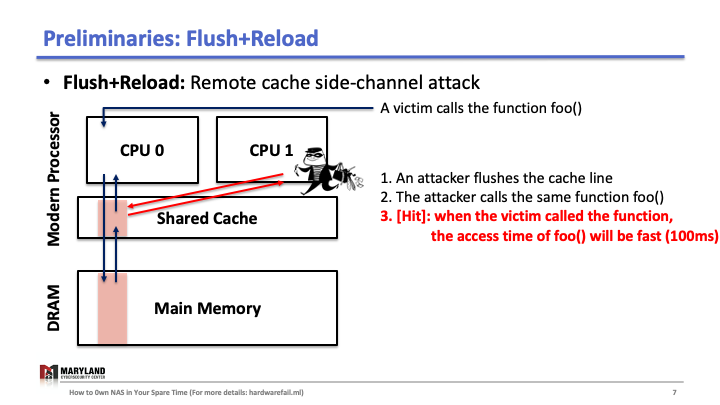
Suppose that your process runs the function foo() on core A, then A loads the instructions for foo() from main memory, executes them, and the instructions are stored in the cache for later (Slide 1-2). If your process runs 1 again, the second execution will be faster than the first as A doesn’t need to load foo() from memory (Slide 3); it loads from the cache.
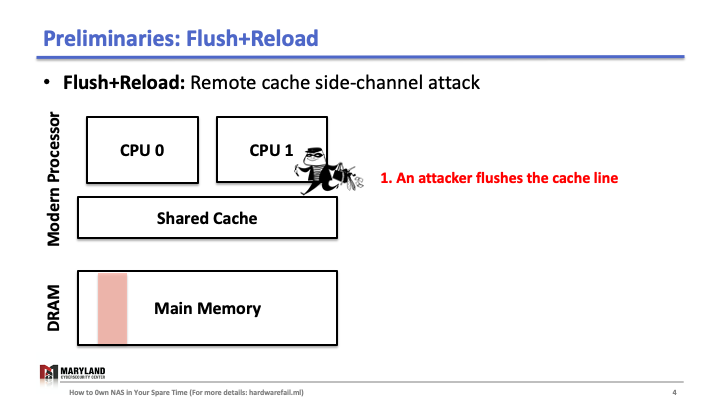
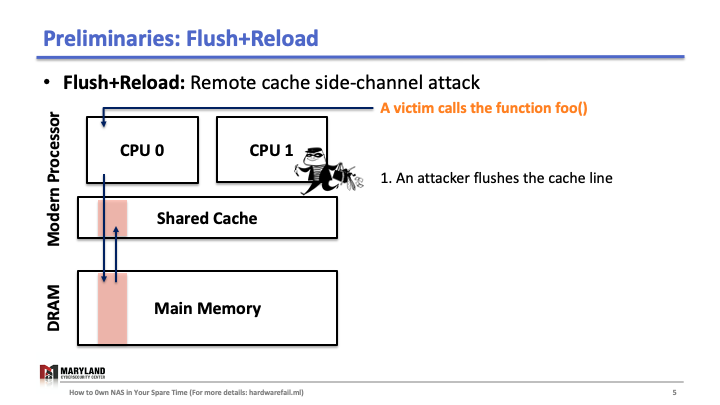
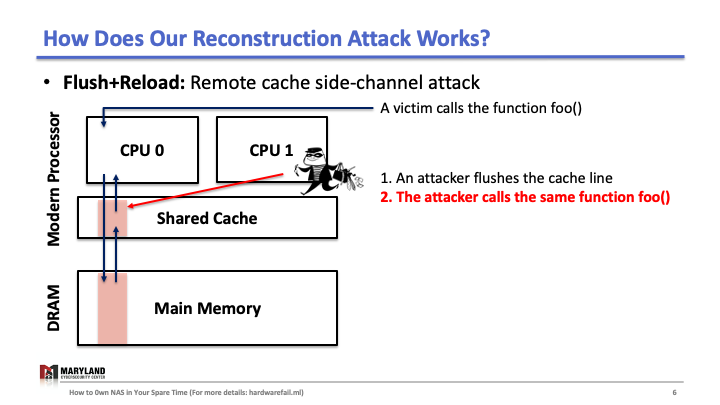
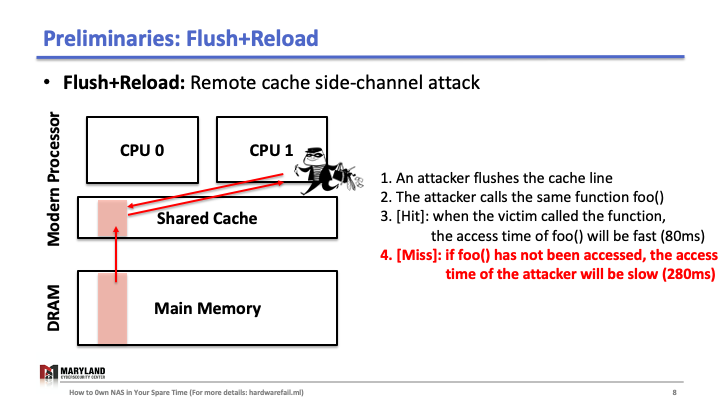
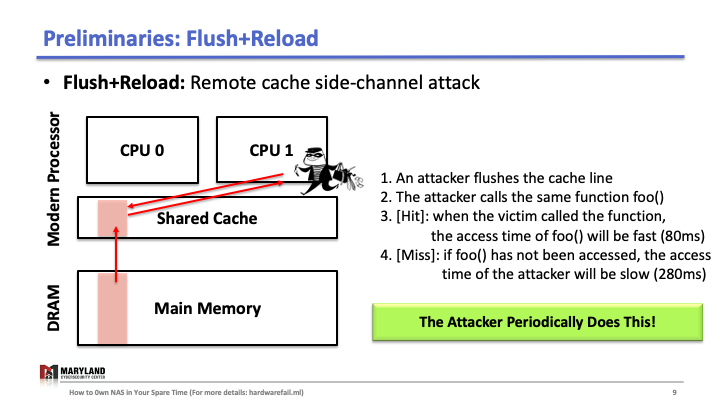
Now, let’s assume the attacker runs her process on core B, co-located in the same CPU. Since the last-level cache is shared between cores, the attacker can flush the stored function foo() in the cache by using clflush instruction—an instruction that can be invoked by any process (Slide 4-5). Then, the attacker calls the function foo() again (Slide 6). If the execution of foo() is fast (< 100ms), it means some other process ran the foo() before the attacker tried to reload it (Slide 7). Otherwise, it means no process ran foo() before the attacker (Slide 8). A Flush+Reload attacker repeats these steps periodically (every 2000 cycles), monitoring a list of functions and identifies the sequence of function calls that the victim ran while processing an input (Slide 9).
Prior work monitors the list of functions associated with cryptographic computations to extract private keys, but in our case, we monitor the functions in open-source deep learning frameworks, PyTorch or TensorFlow.
Seems like you have what you want, what are the challenges?
We will explain how noisy it is and what our secret process is that makes the data clean below.
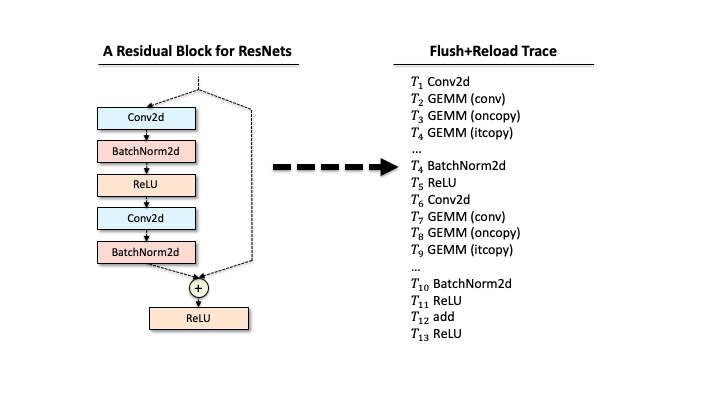
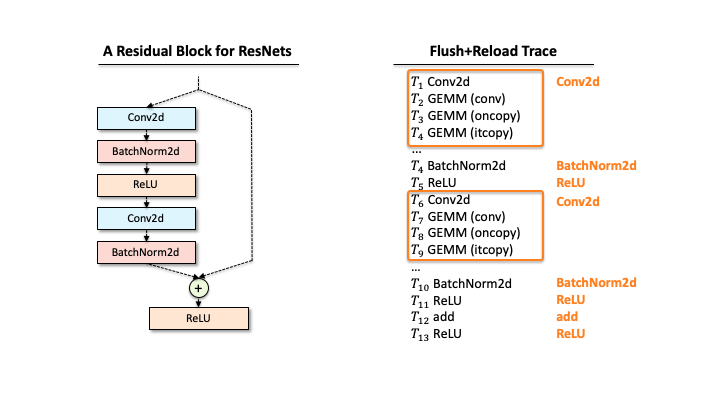
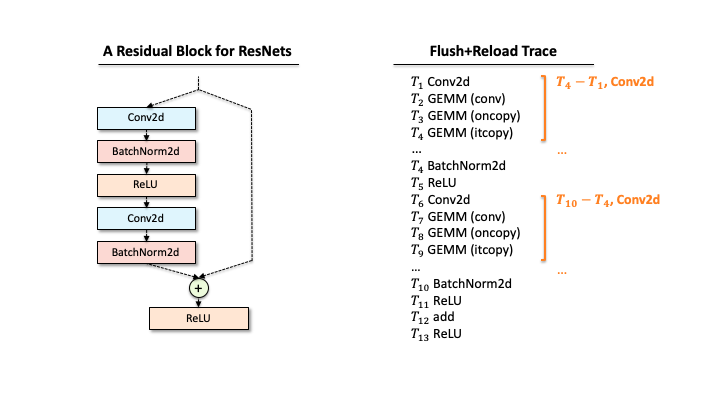
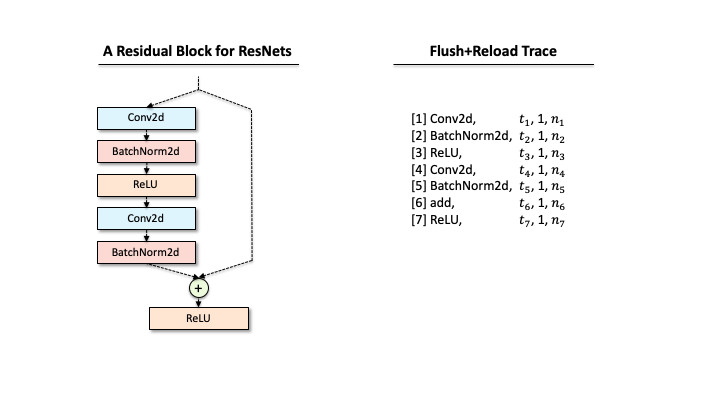
Suppose that a victim has one ResNet block, and our attacker extracted the functions via Flush+Reload while the block processes a single input. As you can see in Slide 1, the raw trace contains the list of functions corresponding to deep learning computations. The first step for the attacker is to identify a block of computations associated with each layer. For example, in Slide 2, we found that Conv2d has a block of sequential computations (Conv2d, GEMMs, …). Second, the raw trace also has the timing information, i.e., when each computation was called. Hence, subtracting two subsequent invocation times gives the time taken for processing each layer (Slide 3). Third, our attacker counts the occurrences of different GEMM computations within each block. This number includes the details of matrix multiplication operations. Finally, our attacker has a much better trace in Slide 4.
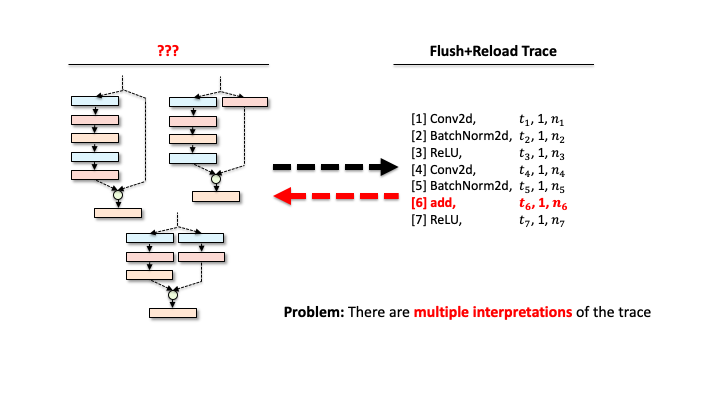
add is a binary operator, and there are multiple ways to compose branches.
It’s still not an easy task to reconstruct the victim’s DNN architecture (one ResNet block) from the processed trace, as one trace could correspond to multiple network architectures. For instance, in the above figure, the trace contains the binary operator add that requires two operands from the previous layer. Due to this configuration, our attacker leads to consider multiple architectures with different connections of preceding layers (1-5). Recall that our attacker also wanted to estimate the architecture details, e.g., the configuration of each layer like kernel sizes, or in/out channels). The number of network architectures possible increases exponentially.
Prior work [3] has limitations in solving this issue; they assume the attacker knows the architecture family. For instance, our attacker has a priori that the victim’s architecture stems from ResNets. However, this easy solution cannot apply in our scenario as the attacker aims to reconstruct unique network architectures. Such architectures cannot be approximated by knowing generic architecture families.
What was your intuition to solve the last mile problem?
Our work focuses on the fact that deep learning operations have regularities. Incorporating those regularities into the reconstruction process, we thought our attacker doesn’t have to deal with an exponential number of possible network architectures. In our example:
- [Connections] The layers in an architecture run in sequential order. In the ResNet block, one branch will be computed first, the other branch will execute, and then
addwill be done. - [Connections] The
addoperation must have two inputs from two different branches. - [Configurations] The time taken for
Conv2doperation is proportional to the size of matrix multiplications. For instance, if the kernel size is larger, the computation will take longer. - [Configurations] The output from
ReLUhas the same dimension as its input. - [Configurations]
BatchNorm2ddoesn’t change the input dimensions likeReLU. - [Configurations] Two input tensors for
addoperation must have the same dimension.
Okay. How do you design your reconstruction process?
Our reconstruction procedures consist of two steps:
- Generation: The attacker can generate the candidate network architectures from the Flush+Reload trace based on the invariant rules that we found before. Using the rules, our attacker reduces the number of candidates significantly.
- Elimination: Our attacker estimates the time for each computation taken and prunes the incompatible candidates. The time is used to approximate the architecture details sequentially starting from the input dimension. When the output dimension from a candidate architecture does not match with the observation, we eliminate.
What does that mean? Let’s check a reconstruction of MalConv to illustrate this process.
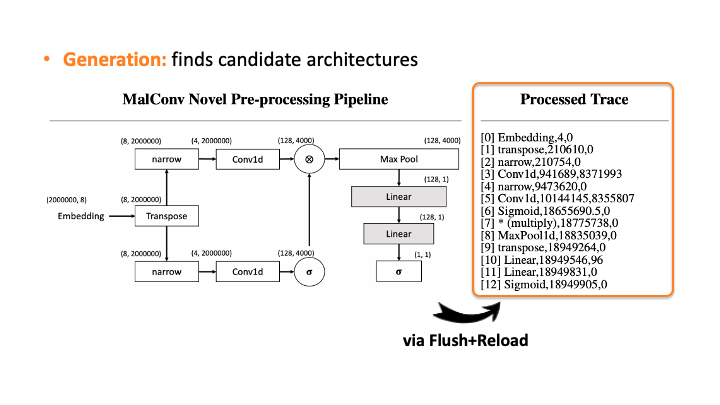
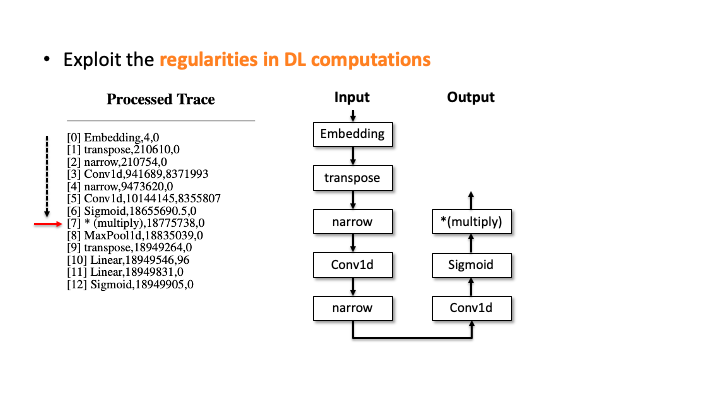
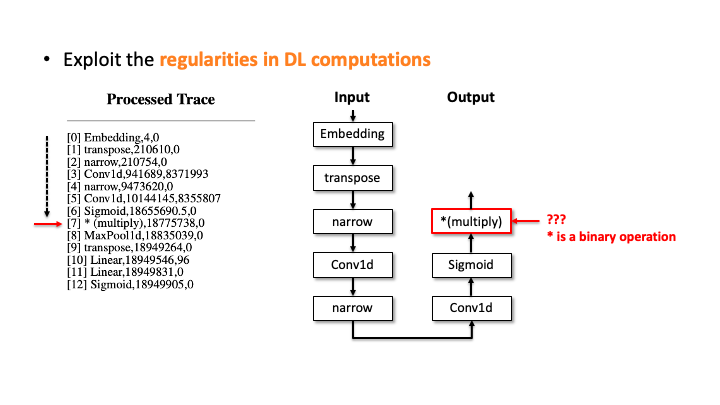
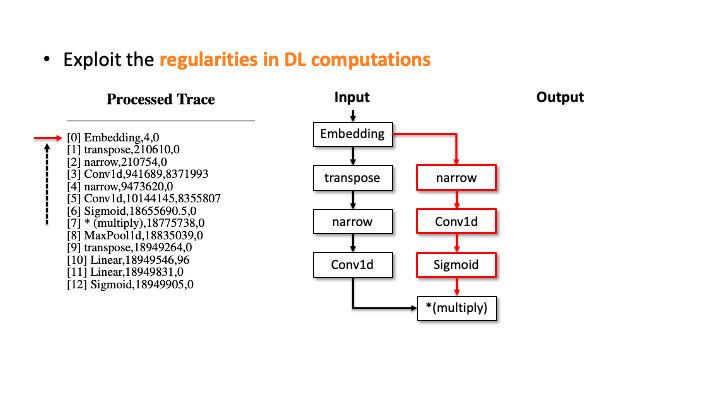
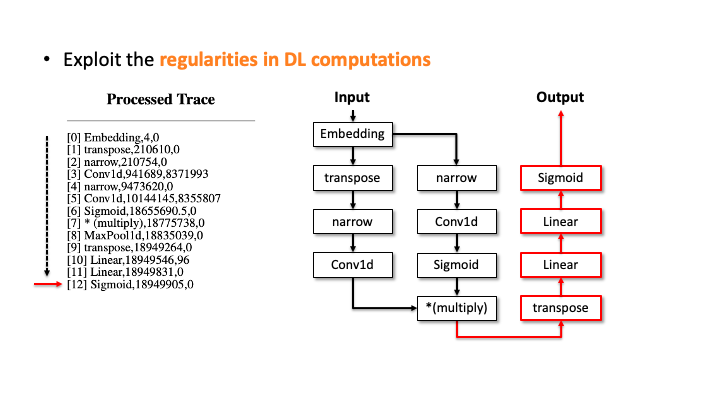
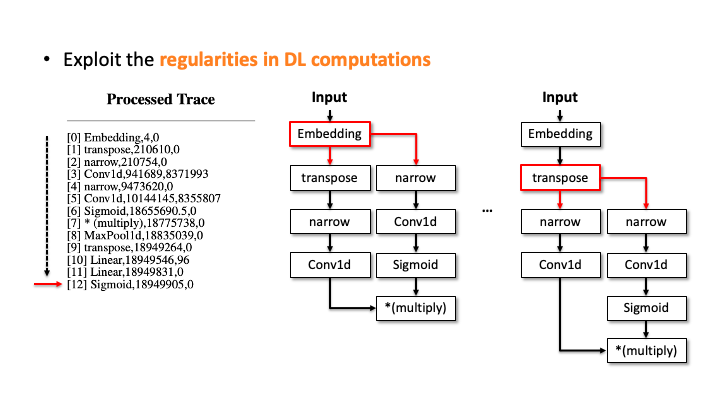
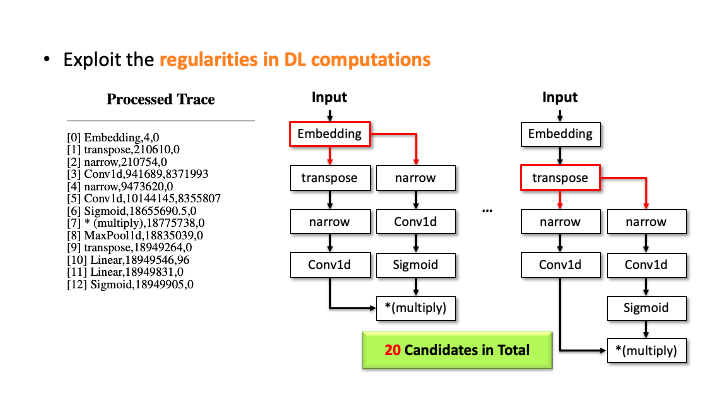
In the figure above, using Flush+Reload, our attacker generates the trace on the right side of Slide 1. You can see the trace contains the sequence of deep learning computations, the type of each computation, and the start and end time of each computation. Based on this trace, the attacker exploits the invariant rules (regularities) for a generation. Considering the first seven computations, our attacker can generate the candidate architecture on the right side of Slide 2; all layers are connected sequentially. However, we know the * (multiply) is a binary operator, which requires two operands like add, but this candidate has one (Slide 3). So, our algorithm traverses back to the first computation and generates a branch so that * (multiply) rule can be satisfied (Slide 4). Our algorithm recursively performs this process until we reach the last computation, and this process will return multiple candidates (Slide 5-6). For MalConv, we had 20 candidate network architectures in total; two of them are shown in Slide 7.
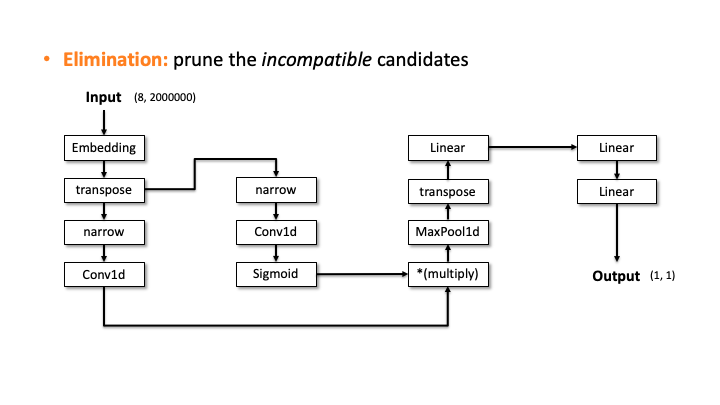
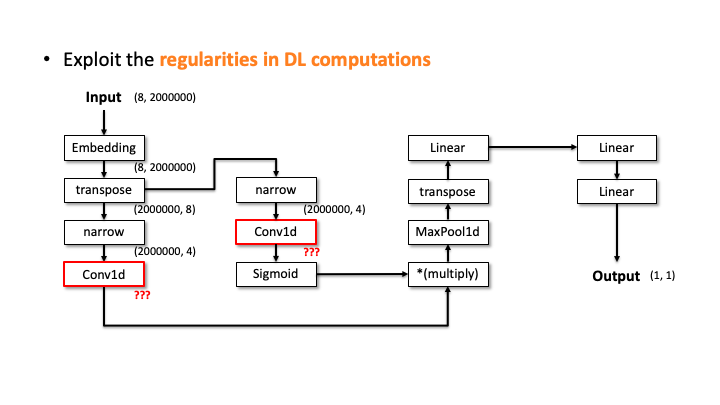
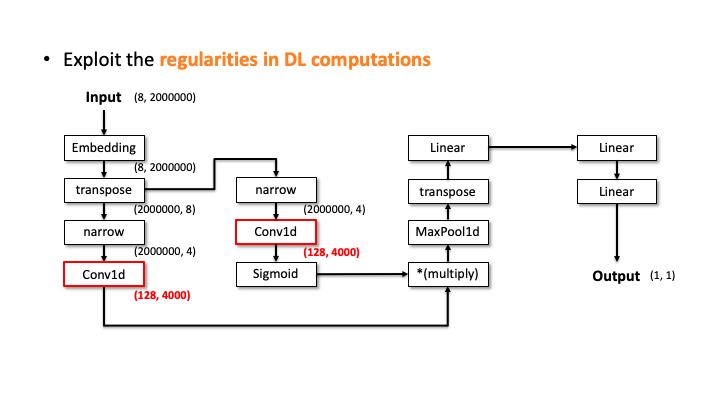
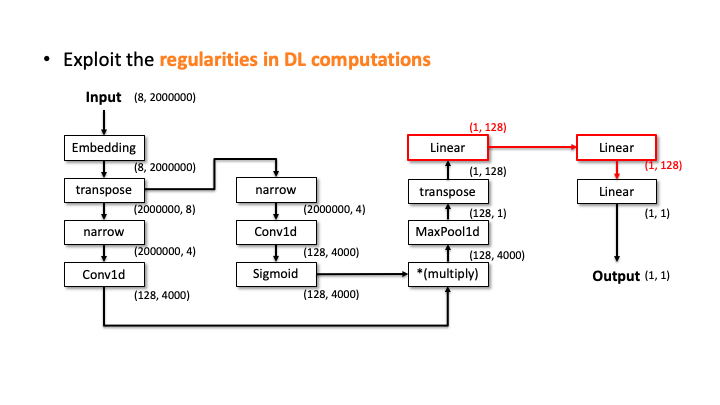

Our attacker then performs the elimination process to prune the incompatible candidates. We do this by estimating the architecture details, i.e., layer configurations, for each of the 20 candidates. Let’s see how it works with the above slides; we show one of the candidates and denote the input and output dimensions (Slide 1). Starting from the input, our algorithm computes the output dimension of each layer based on the estimated configuration of each layer. In Slide 2, you can see the Embedding didn’t change the input dimension, transpose swaps the two elements, and narrow reduces the smaller dimensions into two. But, for the Conv2d, it’s difficult to estimate the output dimension as we don’t know the kernel size, stride, and in/out channels. To solve this issue, the attacker uses the timing information profiled in advance. Using this information, we estimate all the possible configurations for Conv2d. We choose (output channels, kernel size) = (128, 4000) in Slide 3. We proceeded and did the same estimation for Linear (Slide 4). In Slide 5, our algorithm finally estimates the output dimension. The algorithm compares this dimension to the known output dimension. If they don’t match, the algorithm prunes this candidate and moves onto the next one. We do this for this MalConv architecture and ProxylessNAS-CPU architecture, and in both cases, only one architecture remains that has 0% error.
[Reconstructing ProxylessNAS-CPU] When we reconstruct the unique deep learning architecture found from NAS, ProxylessNAS-CPU, our attacker knows the search space of NASNet. This is a fair assumption as the search space is known to the public; however, unlike prior work, we do not assume our attacker knows the architecture family (backbone). Knowing the search space does not, however, reduce the amount of efforts by our attacker sufficiently in reconstruction. The unique architectures found from the NAS process commonly are wide and deep, and they include multiple branch connections. Thus, our attacker requires to consider exponential number of candidate computational graphs and the computation parameters, which makes the attack infeasible. To tackle this issue, we focus on the NAS procedure—this process factorizes the entire architecture into blocks (or cells) by their functions. In ProxylessNAS-CPU, the architecture is composed of normal cells and reduction cells.
To identify the blocks composing the ProxylessNAS-CPU architecture, we utilize the frequent subsequence mining (FSM) method. Our FSM method is simple: we iterate over the Flush+Reload trace with the fixed windows and count the occurrences of each subsequence. Since the attacker knows that in the search space that the victim uses, a maximum of nine computations is used to compose a block, we consider the window size from one to nine. Once we count the number of occurrences for each subsequence (candidate blocks), and we prune them based on the invariant rules in the search space: (1) a Conv2d operation is followed by a BatchNorm, (2) a block with a DepthConv2d must end with a Conv2d and BatchNorm, (3) a branch connection cannot merge (add) in the middle of the block, and (4) we take the most frequent block in each window. We identified the 9 blocks for ProxylessNAS-CPU. We then run the generation process of reconstructing candidate computational graphs with the blocks instead of using each computation in the trace. For more details, we recommend readers to check out our paper.
Cool! Can I defend my unique architecture against your attack?
Utilizing insight from cases that pose difficulty in the reconstruction process for an adversary, we can discuss several possible defenses against this class of attack. These defenses include padding zeros to the matrix multiplication operands, adding null/useless network operations, shuffling the computation order, and running decoy operations in parallel.
By padding zeros to the matrix multiplication operands, an adversary would have more difficulty in ascertaining the true dimensions of the matrices, making the reconstruction of layer attributes more difficult. However, the downside is: implementing this defense not only increases computation time, but also does not counteract the reconstruction process as matrix multiplication restricts important dimensions to match.
By adding null/useless network operations, a victim can increase the adversary’s reconstruction time, but this does not guarantee protection from reconstruction and adds significant computational overhead, defeating the purpose of finding optimal network architectures.
By shuffling the computation order of different layers of the network, an adversary can make the reconstruction process difficult for an adversary to reconstruct (as the possible candidate architectures increase), but restrictions on computational order still exist as many layers require the results of previous layers to compute. Additionally, this increases the space complexity of DNNs, as the results from layer computation must be stored if the order is shuffled.
By running decoy operations in parallel, a victim could hide actual computations in unnecessary noise (as the adversary cannot discern who called the function, just that it was called). However, this approach introduces additional computational overhead from sharing resources with the victim processes and an adversary still may be able to filter this noise using techniques from the reconstruction process.
In light of the inadequacy of these defenses, our paper exposes a striking vulnerability to deep learning systems that needs further mechanisms to prevent damage to intellectual property rights.
Remember this!
In summary, our work demonstrated that a small information leakage from a hardware side-channel, Flush+Reload, can enable attackers to steal unique deep learning architectures remotely, precisely. As unique deep learning architectures are deployed to a wide range of hardware settings, we require hardware-agnostic defense mechanisms.
Resources
Check out our paper “How to 0wn NAS in Your Spare Time” in this link, and the code to reproduce experiments are in here.
Acknowledgement
Thanks to our collaborators for their constructive feedback on a draft and their contributions to the materials presented in this post.
References
[1] Yarom et al., Flush+Reload: A High Resolution, Low Noise, L3 Cache Side-Channel Attacks, 23rd USENIX Security Symposium, in 2014. [PDF]
[2] Liu et al., Last-Level Cache Side-Channel Attacks Are Practical, IEEE Security and Privacy Symposium, in 2015 [PDF]
[3] Hong et al., Security Analysis of Deep Neural Networks Operating In the Presence of Cache Side-Channel Attacks, arXiv 2018. [PDF]