My research on Active Vision has
concentrated on:
(a): the problem of segmenting a scene
into different surfaces through the integration of visual cues. This is the
heart of the vision processes underlying the perception of space and objects.
(b): the interpretation and
understanding of action
(a) COMPOSITIONAL VISION
Chicken-and-egg problems in early and middle-level vision. The visual world can be decomposed into a collection of surfaces separated by boundaries. Such a surface segmentation may be performed with regard to a property (or set of properties) which varies smoothly along a surface, but is discontinuous at the boundary between two surfaces. Properties like the brightness or color of image pixels are sensor
measurements, and we can imagine a process which finds discontinuities in these properties. However, segmenting an image using properties such as depth, motion, or texture is not directly possible, since these properties are not direct sensor measurements, but are quantities to be deduced. In fact, it turns out that deducing these quantities depends on the segmentation which they would create; therefore, such property estimation and property-based segmentation problems form chicken-and-egg pairs.
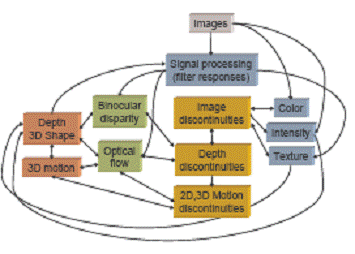
Some examples are: texture and texture-based segmentation, disparity and disparity-based segmentation from stereo images, optical flow and 2D motion-based segmentation from video, 3D motion and 3D motion-based segmentation from video.
In fact, the interdependence among various sub problems is not just restricted to a few chicken-and-egg pairs of problems, but is ubiquitous as indicated by the web of relationships in the figure above that describes the flow of information among various early modules related to the correspondence problem. The architecture underlying this figure has been pieced together using our work in the past several years as well as a number of results from the community. The PhD dissertation of Abhijit Ogale and the results of
Cornelia Fermuller on Uncertainty in Visual Processes were the important components of this architecture.
First, various measurements such as color, intensity, and filter responses are gathered from the input images. The filter responses can be used as inputs to a texture analysis module, as well as local evidence for binocular stereo and motion correspondence modules. Stereo disparity and optical flow both affect and are affected by the estimation of depth discontinuities, shape and depth; therefore, stereo and optical flow will indirectly interact with each other. Shape from X (texture, shading) also influences the estimation of 3D shape. The estimation of depth discontinuities is also affected in certain directions by image discontinuities such as intensity, color or texture discontinuities. Image discontinuities in turn may affect the perception of intensity, color and texture as well, which is indicated by certain visual illusions. Besides depth discontinuities, optical flow is also related to 3D motion discontinuities (i.e., boundaries of independently moving objects) and 3D motion estimation. Ultimately, computed shape feeds back to affect the interpretation of local measurements and samples, and we return back to where we started!
The above scenario can be expanded to contain many more modules, interactions and dependencies than those just described. To solve such chicken-and-egg problems, a compositional approach is required. Compositionality implies seeking joint solutions to interdependent problems, possibly using explicit or implicit feedback; it implies a principle of gradual collaborative commitment to solutions and prevents individual problems from committing too early to myopic solutions without ‘discussion’ with other problems. We are currently working towards the integration of early vision (completing the above figure). Check the page of my research associate Abhijit Ogale for results, demos, papers and code.
(b) A LANGUAGE FOR ACTION
We have been working for some time on recognizing human action from video. This led us to
the
realization a few years ago that human action is characterized by a language. In
fact, actions are represented in three spaces: the visual space, the motor space
and the natural language (i.e., linguistic) space. Therefore, we can imagine that actions
possess at least three languages: a visual language, a motor language, and natural
language. The visual language allows us to see and understand actions, the motor language
allows us to produce actions, and the natural language allows us to talk about actions. We
are developing the phonology, morphology and syntax of these different languages as well
as their relationships.
For results and papers, visit The Grammars of Human Behavior
Here is the abstract of a talk I gave recently at Yale CS/Engineering and at the Cognitive Science
& Human Development Dept. at Vanderbilt.
ARISTOTLE’s DREAM: A
LANGUAGE FOR ACTION
The behaviorome project?
I present
a roadmap to a language for symbolic
manipulation of visual and motor information in a sensori-motor system
model. The visual information is processed in
a perception subsystem which translates a visual representation of
action into our visuo-motor language. We measured a large number of human actions in order to have empirical
data that could validate and support our embodied language for movement and
activity. The embodiment of the language serves as interface between visual
perception and the motor subsystem responsible for action execution. The
visuomotor language is defined using a linguistic approach. In phonology, we define basic atomic
segments that are used to compose human activity. Phonological rules are
modeled as
a finite automaton. In morphology,
we study how visuomotor phonemes are combined to form strings representing
human activity and to generate a higher-level morphological grammar. This
compact grammar suggests the existence of lexical units working as visuo-motor
subprograms. In syntax, we present a
model for visuo-motor sentence construction where the subject corresponds to
the active joints (noun) modified by a posture (adjective). A verbal phrase
involves the representation of the human activity (verb) and timing
coordination among different joints (adverb). In simple terms, human action,
whether visual or motoric, is characterized by a language that we can
empirically discover. Proper interfacing among these languages and a spoken
language (e.g. English) gives rise to the human conceptual system.
The theory
has a number of implications in Engineering (sensor networks and surveillance
systems), cognitive systems and AI (the grounding problem), Linguistics (the
universal grammar). In the second part of the talk I will describe the behaviorome project, in which using
recent technology for measuring sensorimotor activity we build a sensorimotor
corpus. I will discuss how using this corpus and learning technology we could
obtain (learn) the human conceptual system, i.e. ultimately solve the grounding problem.