|
Explicit Multi-Threading (XMT): A PRAM-On-Chip Vision A Desktop Supercomputer For the prior version of this page that includes numerous links (some broken/expired) to news coverage click here . | |||||||||||
|
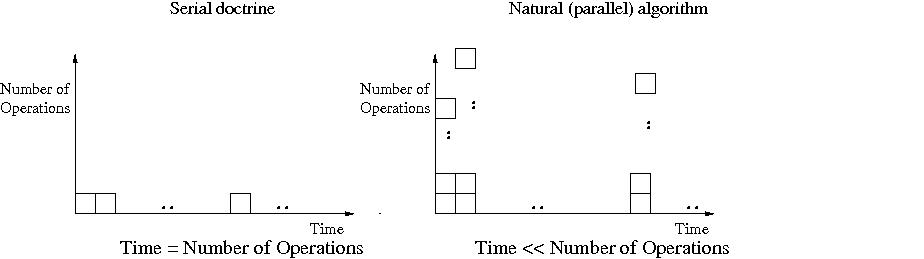
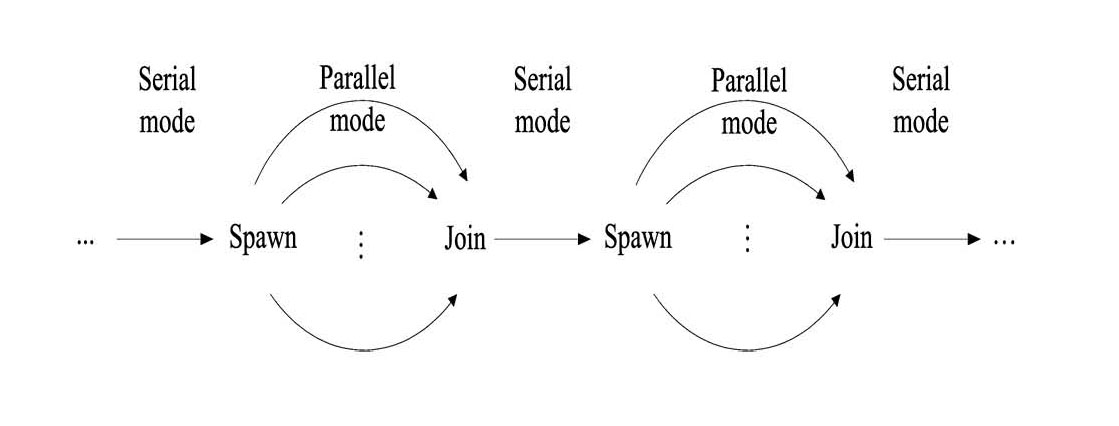
SummaryIn the past, mainstream computers used a single processor core. Nearly a decade ago all mainstream commercial computers switched to using multiple cores (due to technical reasons, such as overheating), and became known as multi-cores. Consequently, the XMT vision for a desktop many-core supercomputer, introduced in 1997, became relevant for mainstream computing. XMT is as timely today: policy reports, such as The Future of Computing Performance: Game Over or Next Level?, recognize that the field is desperate for alternative multi-core ideas, as well as competition. To appreciate how serious the situation is, note the extremely low level of application innovation in general-purpose desktop computing (excluding graphics) during the last decade (e.g., in comparison to the internet and mobile markets, or the increasingly specialized machine-learning platforms). The main reasons for the current situation are: 1. Commercial multi-core machines have, so far, failed to generate a broad base among application programmers; most programmers simply find these multi-cores too difficult to program effectively; indeed, the Game Over report points out that Only heroic programmers can exploit the vast parallelism in today's machines . 2. In turn, the repelling of programmers took the steam out of desktop computing: not having enough ready-to-deploy applications for multi-cores weakened the business case for larger investment in better multi-core hardware. It is also relevant to point out that by the time competition among machine vendors was needed to give the market true choice towards the transition to multi-cores, most brand names of the 1990s (e.g., Apple, DEC, IBM, Motorola, Sun) have already dropped out from the desktop hardware market.XMT aspires to break this impasse. Rather than sidestep ease-of-programming, or treat it as afterthought, XMT builds on PRAM -- the foremost parallel algorithmic theory to date. XMT appears to be the only active architecture research project in the computer science community today that handles ease-of-programming as a first class constraint. Indeed, the following quote captures the programming difficulty for current commercial systems: In practice, exploiting eight cores means that a problem has to be broken down into eight pieces -- which for many algorithms is difficult to impossible. The piece that can't be parallelized will limit your improvement, Paolo Gargini (Intel), Nature, 2/2016. Status report 2019. A new "capstone" for the overall XMT effort was reported in this paper, which demonstrated that XMT can be programmed in a lock-step manner. To appreciate the significance of this accomplishment, note that textbooks on (PRAM) parallel algorithms employ just one command: "pardo" in their pseudo-code for parallel algorithm. The new contribution is that this command alone is all that is needed from the parallel programmer. Namely, such pseudo-code can imported as-is into the XMT parallel program. The surprising result is that such program achieves the same performance as the fastest hand-optimized threaded code, which is what XMT programmers had to produce prior to this work. 70 students at a single high-school (Thomas Jefferson High School for Science and Technology in Alexandria, Virginia) have successfully programmed XMT in Spring 2019 for a total of 753 at that high school alone since 2009. A similar number is already enrolled for the 2019/20 school year. For less recent work, see the presentation of a paper entitled: Can Cooling Technology Save Many-Core Parallel Programming from Its Programming Woes? at the Compiler, Architecture and Tools Conference (CATC), Intel Israel Development Center (IDC), Haifa, Israel, November 23,2015, and most recently this 2017 Technion and IDC talk Old (2012-3) status report. Using our hardware and software prototypes of XMT, we recently demonstrated parallel speedups that beat all current platforms by orders of magnitude on the most advanced parallel algorithms in the literature, including for max-flow, graph biconnectivity and graph triconnectivity, , as well for our 2013 parallelization of the engine (known as the Burrows-Wheeler algorithm) that drives the Bzip2 text compression standard. This stress test validates our 30-year old hypothesis that the PRAM algorithmic theory can save parallel computing from its programming woes, while traversing an architecture narrative that has belittled for decades the PRAM theory, stipulating that it is too simplistic for any existing or future parallel machine. The XMT/PRAM advantage is especially important for the so-called, irregular, fine-grained programs that all commercial platforms to date fail to support effectively.
If reading one XMT paper, this is the one:* U. Vishkin. Using simple abstraction to reinvent computing for parallelism. Communications of the ACM (CACM) 54,1, pages 75-85, January, 2011. Anecdote: The ACM recorded a total of around 18,000 downloads of this paper. Navigate this page:
|
Why is the problem that XMT solves of broad interest?General-purpose computing (your personal computer) is one of the biggest success stories of technology as a business model. Intel's former CEO, Andy Grove, coined the term Software Spiral to describe the following process: improvements in hardware lead to improvements in software that lead back to improvements in hardware. Dr. Grove noted that the software spiral has been a powerful engine of sustained growth for general-purpose computing for quite a few decades. The bad news is that this spiral is now broken. Until recently, programmers could assume that computers execute one operation at time. To programmers, the improvements in hardware simply looked as executing single operations faster and faster. Software developers (programmers) could continue to write programs in the same way, knowing that the next generation of hardware will run them faster. Technology constraints are now forcing the industry to base all its new hardware on parallel computing, which executes many concurrent operations at a time. This hardware requires a complete overhaul of the way that software needs to be written. Unfortunately, as hardware vendors recognize, this hardware can be too demanding on software developers. For example, Chuck Moore, Senior Fellow, AMD said in 2008: "To make effective use of multicore hardware today, you need a PhD in computer science". Evidence that not much has changed is reflected in the following July 2010 title by Prof. David Patterson, University of California, Berkeley: The Trouble with Multicore: Chipmakers are busy designing microprocessors that most programmers can't handle. Keeping the general-purpose "Software Spiral" on track, which requires reinventing both software and hardware platforms for parallel computing, is one of the biggest challenges of our times. Parallel software productivity problems are breaking the spiral, and failing to resolve the problem can cause a significant recession in a key component of the economy. What specific problem does XMT solve? And what is unique about the XMT solution?XMT provides a complete solution for the way future computer should be built (hardware) and programmed (software). Unlike other contemporary computers, XMT is based on the only approach that was endorsed by the theory of computer science for addressing the intellectual effort of developing parallel computer programs (or parallel algorithms). The advanced computers that the industry currently builds are very difficult to program, while even high school student can program XMT. In fact, XMT programming has been successfully taught to high school students. To appreciate the significance, simply contrast this fact with the above quote by Mr. Moore, AMD or Prof. Patterson's title.
Explaining parallel computing at Middle School:What Grown-Ups Do Not Understand About Parallel Programming - The Peanut Butter and Jelly Story.High School Teacher on His Experience with XMTFor a 4-part interview with Shane Torbert a Computer Science and Mathematics teacher at Thomas Jefferson High School for Science and Technology, Alexandria, Virginia, click Part 1: Why XMT (m4v player, 4 minutes) , Part 2: Ease of Use (m4v player, 3 minutes) , Part 3: Content Focus (m4v player, 3 minutes) , and Part 4: Final word to teachers (m4v player, 3 minutes) . Mr. Torbert studied by himself (PRAM algorithm and) XMT programming from material available through this webpage. The interview was presented in a Keynote at the CS4HS Summer Workshop at Carnegie-Mellon University that can be found under Talks below. For a paper on his experience, see the Parallel Computing session at SIGCSE, Milwaukee, WI, March 2010.
High School Student on His Experience with XMT Some Quotes from Experts
- The single-chip supercomputer prototype built by Prof. Uzi Vishkin's group uses rich algorithmic theory to address the practical problem of building an easy-to-program multicore computer. Vishkin's XMT chip reincarnates the PRAM algorithmic technology developed over the past 25 years, uniting the theory of yesterday with the reality of today.
- I am happy to hear of the impending announcement of a 64 processor prototype of Uzi Vishkin's XMT architecture. This system represents a significant improvement in generality and flexibility for parallel computer systems because of its unique ability to exploit fine-grain concurrency. It will be able to exploit a wider spectrum of parallel algorithms than today's microprocessors can, and this in turn will help bring general purpose parallel computing closer to reality.
- Today's multi-core processors support coarse grain parallelism. Professor Vishkin has defined a new parallel architecture that supports extremely fine-grained threading. On XMT, a program can be profitably decomposed into tasks as small as 10 instructions. With a complete programming model and an impressive FPGA-based prototype, Professor Vishkin is proposing a compelling alternative design for future microprocessors.
Credit should go to the whole XMT team | ||||||||||
On-Line Tutorial on Parallel Programming through Parallel Algorithms The following 8 items are available for download following a full day tutorial to high-school students at
the University of Maryland on September 15, 2007. The 9th item is a September 2008 software release of of the XMT environment.
The 10th item links to the selection of material in a recent high-school course on the topic.
By Summer 2009, 100 K-12 students had already studied XMTC programming.
The September 15, 2007 tutorial kicked off an informal parallel programming course for high school students. Beyond the opening tutorial,
the course was conducted through a weekly office hour that Scott Watson, an undergraduate teaching assistant, held at Montgomery Blair High School.
Item 8 above, the home page for the informal course, provides practical guidance on using the XMT FPGA computer and links to 8 programming assigments.
Software Release of the XMT EnvironmentThis public software release allows you to use your own computer for programming on an XMT environment and experimenting with it, as pointed out in Item (9) above. Download the software release. Teaching Parallelism and Full On-Line CourseWe provide all the material needed for a course on parallel algorithms coupled with XMTC programming assignments: video-recorded lectures for the full semester, class notes, dry homework assignments, and programming assignments along with a complete software environment:see the parallel algorithms course as taught in 2009 to graduate students at UMD. We also explain the need for such a course. Download teaching suggestions. Talks (for talks presenting a particular publication, look under Publications)· (General talk:) Explicit Multi-Threading (XMT): A Theorist's Proposal for a Big Little Computer System. Download talk (27 slides). Versions of the SPAA'98 talk were given at IBM Haifa Research Laboratory (8/98), University of Maryland Computer Engineering Colloquium (9/98), The Computer Architecture and Parallel System Laboratory, University of Delaware (10/98), The Center for Research on Parallel Computation, Rice University (10/98), CASES98: Workshop on Compiler and Architecture Support for Embedded Systems, Washington, DC (12/98), New York University (12/98), IBM T.J. Watson (12/98), the Workshop on Parallel Algorithms (WOPA'99), Atlanta (5/99), Technion - Israel Institute of Technology (5/99), and Georgia Institute of Technology (3/00). · (Specialized talk:) Experiments with
list ranking for Explicit Multi-Threaded (XMT) instruction parallelism (by · (General talk) What to do with all this
hardware? Could the PRAM-On-Chip architecture lead to upgrading the WINTEL
performance-to-productivity platform? Download
abstract. Download talk
(postscript, slides in 6 quads) or (pdf, 6
quads) Invited talks were given at the Intel Microprocessor Research Lab
(MRL), Santa Clara, CA, and at Microsoft Research, Redmond, WA, in January
2002, and at IBM T.J. Watson Research Center, Yorktown Heights, NY, in June
2002. · (Specialized talk) Bending Light for Multi-Chip Virtual PRAMs? (12 slides), 3rd Workshop on Non-Silicon Computation, held in conjunction with the 31st International Symposium on Computer Architecture (ISCA 2004), June 19-23, 2004, Munich, Germany. · (Specialized talk) Pilot
development time productivity study on the Spring 2004 course Parallel
Algorithmics (12 slides), DARPA's High Productivity Computing Systems
Program and Productivity Summit, · (General talk) PRAM-On-Chip: A Quest for
Not-So-Obvious Non-Obviousness. Download
abstract . Download
talk (pdf, 33 slides) . Invited talks were given at Intel Research Lab,
Petach Tiqwa ( · (General talk) Can Parallel Computing Finally Impact Mainstream Computing? Download abstract . Download talk (pdf, 40 slides) . Invited talks were given at Microsoft Research and Intel Research Pittsburgh, 3/2005 and 4/2005. · (General talk) PRAM on Chip: Advancing from Parallel Algorithms to a Parallel System. Download talk (pdf, 46 slides) . Talks were given at Sandia National Lab 3/2006 and the UMIACS Workshop on Parallelism in Algorithms and Architectures, May 12, 2006. · (General talk) PRAM-On-Chip Vision:
Explicit Multi-Threading (XMT) Technology. Download
talk (pdf, 53 slides) . Distinguished EECS Colloquium, · (Panel discussion position) For General-Purpose Parallel Computing: It is PRAM or never (pdf, 17 slides) . Microsoft Workshop on Manycore Computing, Seattle, Washington, June 20-21, 2007 . · (General talk) Towards Realizing a PRAM-On-Chip Vision. Download talk (pdf, 60 slides) . Keynote, Workshop on Highly Parallel Processing On Chip (HPPC) , August 28, 2007, in conjuction with Euro-Par 2007, Rennes, France. · (General talk) The eXplicit MultiThreading (XMT) Parallel Computer Architecture - Next generation mutli-core supercomputing. Download talk (pdf, 64 slides) . Talk given to Intel, December 13, 2007 and elsewhere. · (Panel discussion presentation at IPDPS08, April 16, 2008, Miami, Florida) Topic of panel: How to avoid making the same mistakes all over again or... how to make the experiences of the parallel processing communities useful for the multi/many-core generation. Download presentation (pdf, 6X2 slides) . Program of IPDPS08 . · Disruptive Long-Term (~2018) R&D Goal: Easy-to-Program Many-Processor Supercomputer (ppt, 18 slides) . Department of Energy (DOE) Institute for Advanced Architecture and Algorithms(IAA) Interconnection Networks Workshop, July 21-22, 2008, San Jose, California. · (General talk) The PRAM-On-Chip Proof-of-Concept. Download talk (pdf, 42 slides) . Workshop on Theory and Many Cores (T&MC), University of Maryland, May 29, 2009. See also: Introduction to the Workshop. Download talk (pdf, 8 slides) . · Parallel Programming for High Schools. Download talk (ppt, 48 slides) . Keynote (joint with Mathematics Education Professor Ron Tzur, Purdue University, Mathematics Education graduate student David Ellison, University of Maryland and University of Indiana, and George Caragea, graduate student in the XMT team) at CS4HS Summer Workshop, Carnegie-Mellon University, July 24-27, 2009. The talk incdlues a 4-part interview with Shane Torbert a Computer Science and Mathematics teacher at Thomas Jefferson High School for Science and Technology, Alexandria, Virginia. For the interview click Part 1: Why XMT (m4v player, 4 minutes) , Part 2: Ease of Use (m4v player, 3 minutes) , Part 3: Content Focus (m4v player, 3 minutes) , and Part 4: Final word to teachers (m4v player, 3 minutes) . Mr. Torbert studied by himself (PRAM algorithm and) XMT programming from material available through this webpage. Note also pictures from a Montgomery County (Maryland) Public Schools middle-school summer camp (for rising 6-8th graders who are 10-13 year old) from underrepresented groups, July 13-24, 2009. · (Panel discussion presentation at the Workshop on Highly Parallel processing on Chip (HPPC), August 25, 2009, as part of Europar 2009, Delft, The Netherlands) Topic of panel: Are Many-Core Computer Vendors on Track? Download presentation (ppt, 12 slides) . Panel summary . · (General talk)
No Need to Constrain Many-Core Parallel Programming. Download
abstract.
· Position: Reinvention of computing for many-core parallelism requires addressing programmer's productivity. Download extended presentation (ppt, 18 slides) . Presentation at the Indo-US Workshop on Parallelism and the Future of High-Performance Computing, January 9-10, 2010, Bangalore, India . · (General talk) Using Simple Abstraction to Guide the Reinvention of Computing for Parallelism. Parallel@Illinois Distinguished Lecture and a Computer Science Colloquium, University of Illinois, Urbana-Champaign, March 15, 2010. Abstract, video, and slides from the Parallel@Illinois Archives. Power point slides are available here (pptx, 52 slides). Talks with the same title were given at the Hebrew University, Jerusalem, Israel, May 30, 2010 and University of Vienna, Austria, June 2, 2010. Power point slides are available here (pptx, 52 slides). · (General talk) From asymptotic PRAM speedups to easy-to-obtain concrete XMT ones, invited talk, DIMACS Workshop on Parallelism: A 20-20 Vision, March 14-16, 2011. Download abstract. Download slides (pdf, 24 slides). · G. Caragea, J. Edwards and U. Vishkin. Can PRAM Graph Algorithms Provide Practical Speedups on Many-Core Machines? contributed talk, DIMACS Workshop on Parallelism: A 20-20 Vision , March 14-16, 2011. Get the slides for the talk by James Edwards from DIMACS webpage. · U. Vishkin. Panel: looking back at 25 years of IPDPS, Anchorage, Alaska, May 13, 2011. Download slides. · (General talk) Current mainstream computing: If in a hole, should we keep digging? Abstract, presented on June 2, 2011 at the Computer Science Department, University of California, San Diego. 61 slides, or link through the UCSD class on Parallel Algorithms Later talks expending on this title were given at ETH Zurich (11/2011), Tel Aviv University (11/2011), Georgetown University (12/2011) and Los Alamos National Lab (1/2012). · U. Vishkin. Panel: Teaching Parallelism, ACM-SPAA, San Jose, California, June 4, 2011. Download slides. · (General talk) Can the Floodgate of General-Purpose Computing Innovation Reopen with Many-Core Parallelism? Computer Science Colloquium, Purdue University, February 23, 2012. · (General talk) Time to Right the Transition to General-Purpose Many-Core Parallelism. Illinois-Intel Parallelism Center (I2PC) Distinguished Speaker Series, April 12, 2012. Video. · (General talk) NIH/NCBI Computational Biology Branch Seminar, April 27, 2012 and NIH/NCI, June 8, 2012. · (Position on research direction) Principles Matter and Can Matter More: Big Lead of PRAM Algorithms on Prototype-HW. Download Uzi Vishkin's abstract and slides. NSF Workshop on Research Directions in the Principles of Parallel Computation, Pittsburgh, Pennsylvania, USA June 28, 2012. · (General talk) IBM T.J. Watson, June 3, 2013. · (General talk) Is General-Purpose Many-Core Parallelism Imminent?. Distinguished Lecture Series, School of Computing Science, Simon Fraser University, June 18, 2013. · (General talk) Computer Science & Engineering Colloquia Series. Washington University, St. Louis, November 1, 2013. · J.A. Edwards and U. Vishkin.High-Bandwidth Communication Avoidance: Oxymoron Or Recipe? Talk to be given by James Edwards. Minisymposium on Minimizing Communication in Linear Algebra, 16th SIAM Conference on Parallel Processing for Scientific Computing, Portland, Oregon, February 18-21, 2014. · U. Vishkin.Making general-purpose computing great again. Joint seminar of Electrical Engineering and Computer Science, Technion, April 20, 2017. A similar was was given also at IDC, the Israel Design Center of Intel. · U. Vishkin.Single-Threaded Parallel Programming for Multi-Threaded Many-Core Design. The School of Informatics, Computing, and Engineering (SICE) CS Colloquium Series, Indiana University: Distinguished Speaker Series, November 2, 2018. · U. Vishkin.How to hold CPU vendors feet to the Software Spiral fire? Abstract. Slides. Workshop on Emerging Models of Colossal Computation, Warsaw, Poland, May 17-19, 2022. · U. Vishkin.Can parallel algorithms reverse the decline of general-purpose CPUs? Workshop on Theory in Practice, The Institure for Data, Econometrics, Algorithms and Learning (IDEAL), Northwesten University, September 11-13, 2022. Program including titles and abstracts. For video recording of the talk go to Monday's talk (after lunch), starting at time 50:26 · U. Vishkin.Empirical Challenge for NC Theory: Can Manycores CPUs enhance automated reasoning? Abstract. Talk. given at LAPIS: Logic and Algorithms for Programming Intelligent Systems, Rice University, June 21, 2023. Publications
· S. Dascal and U. Vishkin. Experiments
with list ranking for Explicit Multi-Threaded (XMT) instruction parallelism
(extended abstract). In Proc. 3rd Workshop on Algorithms Engineering (WAE'99), ·
· D. Naishlos, J. Nuzman, C-W. Tseng, and U. Vishkin. Evaluating
multi-threading in the prototype XMT environment. In Proc. 4th Workshop on
Multi-Threaded Execution, Architecture and Compilation (MTEAC2000),
December 2000 (held in conjunction with the 33rd Int. Symp. on
Microarchitecture MICRO-33). Best Paper Award for MTEAC2000. ·
D. Naishlos, J. Nuzman, C-W. Tseng, and U. Vishkin. Evaluating
the XMT Parallel Programming Model. In Proc. of the 6th Workshop on
High-Level Parallel Programming Models and Supportive Environments (HIPS-6),
April 2001.
· D. Naishlos, J. Nuzman, C-W. Tseng, and
U. Vishkin. Towards a First Vertical Prototyping of an Extremely Fine-Grained
Parallel Programming Approach. The conference version appeared in Proc. 13th
ACM Symposium on Parallel Algorithms and Architectures (SPAA-01)), July
2001. · A. Balkan, G. Qu, and U. Vishkin.
Arbitrate-and-Move primitives for high throughput on-chip interconnection
networks. In Proc. IEEE International Symposium on Circuits and Systems
(ISCAS), SoC Design Technology lecture session ,
· A. Tzannes, R. Barua, G.C. Caragea, and U. Vishkin. Issues in writing a parallel compiler starting from a serial compiler. Draft, 2006. · P. Gu and U. Vishkin. Case Study of
Gate-level Logic Simulation on an Extremely Fine-Grained Chip Multiprocessor Journal
of Embedded Computing, Special Issue on Embedded Single-Chip Multicore
Architectures and related research - from System Design to Application Support,
2, 2 (2006), 181-190. · A. Balkan, G. Qu and U. Vishkin.
Mesh-of-Trees and Alternative Interconnection Networks for Single-Chip Parallel
Processing. In Proc. 17th IEEE International Conference on
Application-specific Systems, Architectures and Processors (ASAP 2006),
· X. Wen and U. Vishkin. PRAM-On-Chip:
First Commitment to Silicon. Brief announcement. Proc. 19th ACM Symposium on
Parallelism in Algorithms and Architectures (SPAA), pp. 301-302, June 9-11, 2007. · A. Balkan, M. Horak, G. Qu, and U.
Vishkin. Layout-Accurate Design and Implementation of a High-Throughput
Interconnection Network for Single-Chip Parallel Processing. Hot Interconnects
2007, · X. Wen and U. Vishkin. FPGA-based prototype of a PRAM-on-chip processor, ACM Computing Frontiers, Ischia, Italy, May 5-7, 2008. Download TR (pdf, 12 pages). Download talk (pdf, 21 slides). · F. Keceli, T. Moreshet, and U. Vishkin. Power study of a 1000-core processor. 17th International Workshop of Logic and Synthesis, Lake Tahoe, Ca, June 4-6., 2008. · A. Balkan, G. Qu, and U. Vishkin. An Area-Efficient High-Throughput Hybrid Interconnection Network for Single-Chip Parallel Processing. 45th Design Automation Conference, Anaheim, CA, June 8-13, 2008. Download TR (pdf, 6 pages). · X. Wen and U. Vishkin. The XMT FPGA prototype/cycle-accurate-simulator hybrid. The 3rd Workshop on Architectural Research Prototyping, WARP08, June 21-22, 2008, Beijing, China, held in conjunction with ISCA 2008. Download extended abstract. Download slides of Xingzhi Wen's talk. · T. DuBois, B. Lee, Y. Wang, M. Olano and U. Vishkin. XMT-GPU: A PRAM architecture for graphics computation. Proc. 37th International Conference on Parallel Processing (ICPP08), Portland, Oregon, September 8-12, 2008. Download TR (pdf, 9 pages). Download talk (pdf, 25 slides). · A. Balkan, G. Qu, and U. Vishkin. Mesh-of-Trees and alternative interconnection networks for single-chip parallelism. IEEE Transactions on VLSI 17,10 (2009), 1419-1432. · G.G. Caragea, A.B. Saybasili, X. Wen and U. Vishkin. Performance potential of an easy-to-program PRAM-On-Chip prototype versus state-of-the-art processor. Proc. 21st ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), pp. 163-165, Calgary, Canada, August 10-13, 2009. Download TR (pdf, 3 pages). Download talk (ppt, 14 slides). · U. Vishkin. Algorithmic approach to designing an easy-to-program system: can it lead to a HW-enhanced programmer's workflow add-on? Proc. International Conference on Computer Design (ICCD), Lake Tahoe, CA, October 4-7, 2009. Download TR (pdf, 4 pages). Download talk (pptx, 47 slides): this is a slightly updated version of the slides following later talks at the Electrical Engineering Department, Technion and Intel, Haifa, October 21 and 22, 2009. Download abstract for these talks. · A. B. Saybasili, A. Tzannes, B.R Brooks and U. Vishkin. Highly parallel multi-dimensional fast Fourier transform on fine- and course-grained many-core approaches. Proc. 21st Conference on Parallel and Distributed Computing Systems (PDCS), Cambridge, MA, November 2-4, 2009. Download TR. · A. Tzannes, G.C. Caragea, R. Barua and U. Vishkin. Lazy binary splitting: A run-time adaptive dynamic work-stealing scheduler. Proc. 15th ACM Symposium on Principles and Practice of Parallel Programming (PPoPP), Bangalore, India, January 9-14, 2010. Download TR (pdf, 11 pages). Download Alex Tzannes's talk (ppt, 39 slides). · S. Torbert, U. Vishkin, R. Tzur and D. Ellison. Is teaching parallel algorithmic thinking to high-school student possible? One teacher's experience. Proc. 41st ACM Technical Symposium on Computer Science Education (SIGCSE), Milwaukee, WI, March 10-13, 2010. Download from the Parallel Computing session at SIGCSE. Download TR (pdf, 5 pages). Talk by Thomas Jefferson High School teacher Shane Torbert (pdf, 24 slides). · M.N. Horak, S.M. Nowick, M. Carlberg and U. Vishkin. A low-overhead asynchronous interconnection network for GALS chip multiprocessor. Proc. 4th ACM/IEEE International Symposium on Networks-on-Chip (NOCS2010), Grenoble, France, May 3-6, 2010. Download TR (pdf, 8 pages). Extended slides of talk by Prof. Steve Nowick, Columbia University (pdf, 84 slides). Journal version: IEEE Transactions on CAD 30,4 (April 2011), 494-507. Special Issue for NOCS 2010. · C.G. Caragea, F. Keceli, A. Tzannes and U. Vishkin. General-purpose vs. GPU: Comparison of many-cores on irregular workloads. Proc. HotPar 2010, University of California, Berkeley, June 14-15, 2010, Download TR (pdf, 7 pages).) Download poster introduction slide (pptx, 1 slide).) Download poster (pptx, 1 slide).) · C.G. Caragea, A. Tzannes, F. Keceli, R. Barua and U. Vishkin. Resource-aware compiler prefetching for many-cores. Proc. 9th Int. Symp. on Parallel and Distributed Computing (ISPDC), Istanbul, Turkey, July 7-9, 2010. Download TR (pdf, 8 pages).) Journal version: International Journal of Parallel Programming, pages 615-638, 2011 Download TR (pdf, 26 pages).) · U. Vishkin. Using simple abstraction to reinvent computing for parallelism. Communications of the ACM (CACM) 54,1, pages 75-85, January, 2011. Download from CACM. [Download TR (pdf, 9 pages); note: the published version should be accessible to many more readers, as it was edited by the CACM.] · U. Vishkin. Algorithms-based extension of serial computing education to parallelism. Workshop on Integrating Parallelism Throughout the Undergraduate Computing Curriculum, in Conjunction with the 16th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming (PPoPP 2011), San Antonio, Texas, February 12, 2011. Download abstract (pdf, 3 pages).) · D. Padua, U. Vishkin and J. Carver. Joint UIUC/UMD parallel algorithms/programming course. First NSF/TCPP Workshop on Parallel and Distributed Computing Education (EduPar-11), in conjunction with IPDPS, Anchorage, Alaska, May 16, 2011. Download abstract (pdf, 2 pages). Download slides. ·
F. Keceli, A. Tzannes, G. Caragea, R. Barua and U. Vishkin.
Toolchain for Programming, Simulating and Studying the XMT Many-Core Architecture.
Proc. 16th International Workshop on
High-Level Parallel Programming Models and
Supportive Environments (HIPS 2011), in conjunction with IPDPS, Anchorage, Alaska, May 20, 2011.
Download paper.
Download slides of Fuat Keceli's talk.
· G.C. Caragea and U. Vishkin. Better speedups for parallel max-flow. Brief announcement. In Proc. 23rd ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), San Jose, California, June 2-4, 2011. Download paper. Download slides of George Caragea's talk. Open source graph algorithms. · N. Crowell. Parallel algorithms for graph problems, May 2011. MSc scholarly paper by a Computer Science student who evaluated XMT for some wide-interest benchmarks. This student was not part of the XMT team. Crowell's work provides independent validation of evidence published by the XMT team on the advantages of XMT. In particular, his experience has been that, beyond developing serial programs for the problems he worked on, the extra effort for producing parallel code was minimal. Download paper. · U. Vishkin. Restoring software productivity crucial to economic recovery: The multi-core dilemma. White paper, the Technology Innovation Program (TIP), National Institute of Standards and Technology (NIST). Input to help TIP focus the TIP program on areas of critical national need. July 2011. Download this single page paper. · F. Keceli, T. Moreshet and U. Vishkin. Thermal Management of a Many-Core Processor under Fine-Grained Parallelism. Proc. 5th Workshop on Highly Parallel processing on Chip(HPPC 2011), August 30, 2011, in conjunction with Euro-Par 2011, Bordeaux, France. · F. Keceli, T. Moreshet and U. Vishkin. Power-Performance Comparison of Single-Task Driven Many-Cores. Proc. 17th IEEE International Conference on Parallel and Distributed Systems (IEEE ICPADS), December 7-9, 2011, Tainan, Taiwan. Download paper. · J.A. Edwards and U. Vishkin. Better Speedups Using Simpler Parallel Programming for Graph Connectivity and Biconnectivity. Proc. International Workshop on Programming Models and Applications for Multicores and Manycores (PMAM 2012), 17th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming( PPoPP'12), New Orleans, LA, February 25-29, 2012. Open source graph algorithms. · A. Tzannes. Advisors: R. Barua and U. Vishkin. Enhancing Productivity and Performance Portability of General-Purpose Parallel Programming. First Prize. ACM Student Research Competition, ACM International Conference on Parallel Architectures and Compilation Techniques (PACT) 2011. · T. Moreshet, U. Vishkin and F. Keceli. Parallel Simulation of Many-core Processors: Integration of Research and Education, in proceedings of the 119th American Society for Engineering Education (ASEE) Annual Conference, June 10-13, 2012, San Antonio, Texas. Download paper. · J.A. Edwards and U. Vishkin. Speedups for Parallel Graph Triconnectivity. Brief announcement. In Proc. 24th ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), Pittsburgh, PA, June 25-27, 2012. Download paper and James Edwards' slides. Also, Open source graph algorithms. ·
J.A. Edwards and U. Vishkin. Truly Parallel Burrows-Wheeler Compression and Decompression. Brief announcement. In Proc. 25th ACM Symposium
on Parallelism in Algorithms and Architectures (SPAA), Montreal, Canada, July 23-25, 2013.
Download SPAA13 paper and
slides. For more detail see the TCS version and its supporting technical reports below.
·
J.A. Edwards and U. Vishkin. Parallel Algorithms for Burrows-Wheeler Compression and Decompression.
Theoretical Computer Science (TCS), 525 (March 2014), 10-22. DOI 10.1016/j.tcs.2013.10.009.
Preprint.
On-line version.
Technical report of the theoretical algorithm.
Technical report of the companion empirical algorithm.
·
U. Vishkin. Is Multicore Hardware for General-Purpose Parallel Processing Broken?
Communications of the ACM (CACM), Volume 57, No. 4, pages 35-39, April 2014.
Viewpoint article and video. The video is entitled: Does humans-in-the-service-of-technology have a future? .
· A. Tzannes, G.C. Caragea, R. Barua and U. Vishkin.
Lazy Scheduling: A Runtime Adaptive Scheduler for Declarative Parallelism.
ACM Transactions on Programming Languages and Systems (TOPLAS), Volume 36 Issue 3, September 2014
Article No. 10.
paper (pdf, 51 pages).
·
S. O'Brien, U. Vishkin, J. Edwards, E. Waks and B. Yang. Can Cooling Technology Save Many-Core Parallel Programming from Its Programming Woes? Compiler, Architecture and Tools Conference (CATC),
Intel Development Center, Haifa, Israel, November 23,2015.
Slides.
Paper.
·
J.A. Edwards and U. Vishkin. FFT on XMT: Case Study of a Bandwidth-Intensive Regular Algorithm on a Highly-Parallel Many Core.
Workshop on Advances in Parallel and Distributed Computing Models, 30th IEEE International Parallel and Distributed Processing Symposium (IPDPS)
May 23-27, 2016, Chicago, Illinois.
Slides.
Paper.
·
F. Ghanim, R. Barua and U. Vishkin.
Poster: Easy PRAM-based High-performance Parallel Programming with ICE.
25th International Conference on Parallel Architectures and Compilation Techninques (PACT)
September 11-15, 2016, Haifa, Israel.
Paper.
·
F. Ghanim, R. Barua and U. Vishkin.
Easy PRAM-based High-performance Parallel Programming with ICE.
IEEE Transactions on Parallel and Distributed Systems 29:2, Feb. 2018.
Paper.
·
J. Edwards and U. Vishkin.
Linking Parallel Algorithmic Thinking to Many-Core Memory Systems and Speedups for Boosted Decision Trees.
4th Annual International Symposium on Memory Systems (MEMSYS)
October 1-4, 2018, National Harbor, MD.
Paper.
·
G. Blelloch, W. Dally, M. Martonosi, U. Vishkin (organizer and panelist), K. Yelick.
Statements for panel discussion on: Architecture-Friendly Algorithms versus Algorithm-Friendly
Architectures.
In Proc. 33th ACM Symposium on Parallelism in Algorithms and Architectures (SPAA), July 2021.
·
J. Edwards and U. Vishkin.
Study of Fine-Grained Nested Parallelism in CDCL SAT Solvers.
ACM Transactions on Parallel Computing (TOPC), 8,3 (18 pages), September 2021. DOI 10.1145/3470639
·
U. Vishkin.
Beyond worst-case analysis: Observed low depth for a P-complete problem. Proc.
The 13th International Workshop on Programming Models and Applications for Multicores and Manycores
(PMAM), April 2, 2022, Seoul, Korea, in conjunction with PPoPP 2022.
Paper.
Slides.
·
W.J. Dally and U. Vishkin. Point, by W.J. Dally: We Must Extend our Model of Computation to Account for Cost and Location. Counterpoint, by U. Vishkin: Parallel Programming Wall and Multicore Software Spiral: Denial Hence Crisis.
Communications of the ACM (CACM) 65,9, 30-34, September 2022. DOI 10.1145/3548784.
Links: Point and
Counterpoint including an embedded video.
Review of this Point/Counterpoint debate on the UMD Electrical and Computer Engineering web site.
·
A. Hari and U. Vishkin. Empirical Challenge for NC Theory. Workshop on Highlights of Parallel Computing,
part of the ACM Symposium on parallelism in Algorithms and Architectures, Orlando, Florida, June 16-19, 2023.
8 US patents have been issued so far: 8,209,690, 8,145,879, 7,707,388, 7,523,293,
7,505,822, 6,768,336, 6,542,918, and 6,463,527. A partial summary of their
content is provided in the paper
Algorithmic approach to designing an easy-to-program system:
can it lead to a HW-enhanced programmer's workflow add-on? (pdf, 4 pages). Proc. International Conference on Computer Design (ICCD), 2009.
The above Prior Generation link leads to older software tools as
well as older supplemental information to XMT publications. This research project is directed by Professor Uzi Vishkin. Funding by the National Science Foundation and the Department of Defense is
graciously acknowledged. Some of the material on this web page, and XMT subpages linked from this page, is based upon work
supported by the National Science Foundation under grants No. 0325393, 0811504 and 0834373. Any
opinions, findings, and conclusions or recommendations expressed in this
material are those of the author(s) and do not necessarily reflect the views of
the National Science Foundation or the Department of Defense. | |||||||||||
{kind=link}
{kind=link}
{kind=link}
{kind=link}