Terminal Brain Damage
Exposing the Graceless Degradation of Deep Neural Networks under Hardware Fault Attacks
Sanghyun Hong,
Pietro Frigo*,
Yigitcan Kaya,
Cristiano Giuffrida*,
and Tudor Dumitraș
University of Maryland, College Park
*Vrije Universiteit Amsterdam
In USENIX 2019
Presentation: 3:50-5:30 P.M (Track 2) [Aug. 14, Wed]
Abstract
Deep neural networks (DNNs) have been shown to tolerate "brain damage" : cumulative changes to the network’s parameters (e.g., pruning, numerical perturbations) typically result in a graceful degradation of classification accuracy. However, the limits of this natural resilience are not well understood in the presence of small adversarial changes to the DNN parameters’ underlying memory representation, such as bit-flips that may be induced by hardware fault attacks. We study the effects of bitwise corruptions on 19 DNN models—six architectures on three image classification tasks—and we show that most models have at least one parameter that, after a specific bit-flip in their bitwise representation, causes an accuracy loss of over 90%. We employ simple heuristics to efficiently identify the parameters likely to be vulnerable. We estimate that 40-50% of the parameters in a model might lead to an accuracy drop greater than 10% when individually subjected to such single-bit perturbations. To demonstrate how an adversary could take advantage of this vulnerability, we study the impact of an exemplary hardware fault attack, Rowhammer, on DNNs. Specifically, we show that a Rowhammer-enabled attacker co-located in the same physical machine can inflict significant accuracy drops (up to 99%) even with single bit-flip corruptions and no knowledge of the model. Our results expose the limits of DNNs’ resilience against parameter perturbations induced by real-world fault attacks. We conclude by discussing possible mitigations and future research directions towards fault attack-resilient DNNs.
Single-Bit Corruptions on 19 Deep Neural Networks
[Methodology]:
We systematically flips the bits in a model, individually, and
quantifies the impact using the metrics we define
[RAD].
[Datasets]:
We use three popular image classification datasets:
MNIST,
CIFAR10,
and ImageNet.
[Networks]:
We conduct our analysis on 19 different DNN models.
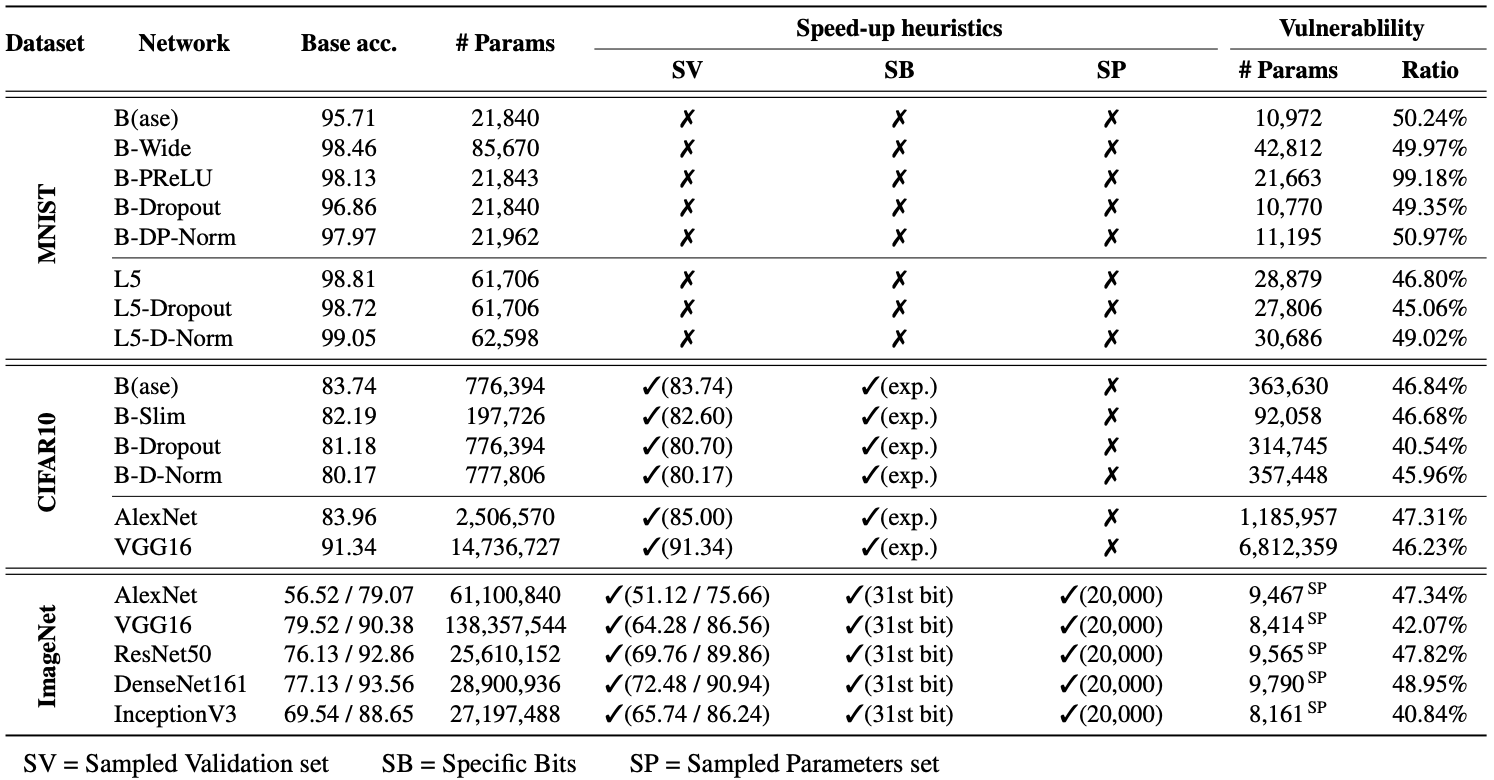
- MNIST: We use 8 DNN models. We define a baseline architecture, Base (B), and generate 4 variants with different layer configurations: B-Wide, B-PReLU, B-Dropout, and B-DP-Norm. We also examine well-known LeNet5 (L5) and test 2 variants of it: L5-Dropout and L5-D-Norm.
- CIFAR10: We use 8 DNN models. We define a baseline architecture (B) and experiment on its 3 variants: B-Slim, B-Dropout and B-D-Norm. We also employ 2 off-the-shelf network architectures: AlexNet and VGG16.
- ImageNet: We use 5 well-known DNNs to understand the vulnerability of large models: AlexNet, VGG16, ResNet50, DenseNet161 and InceptionV3. The details are described in our paper.
- Achilles bit: A bit in a model parameter (over 32-bits), when the bit flips, it causes the RAD > 0.1.
- Maximum RAD: The maximum RAD inflicted by the flip of an Achilles bit.
- Vulnerability: The percentage of vulnerable parameters in a DNN model.
The above table presents the results of our experiments on single-bit corruptions, for 19 different DNN models. We use 3 speed-up heuristics (SV, SB, and SP) for the larger models, respectively. We reveal that an attacker, armed with a single bit-flip attack primitive, can successfully cause indiscriminate damage [RAD> 0.1] and that the ratio of vulnerable parameters (that we examined) in a model varies between 40% to 99%; depending on the model. We also found that every model has at least one Achilles bit that inflicts maximum RAD over 0.9 and up to 1.0.
Characterization of this Vulnerability
Here, we characterize the interaction how the features of a parameter’s bitwise representation govern its vulnerability. We also continue our analysis by investigating how various properties of a DNN model affect the model’s vulnerability to single bit-flips.
[The impact of the bit position]:
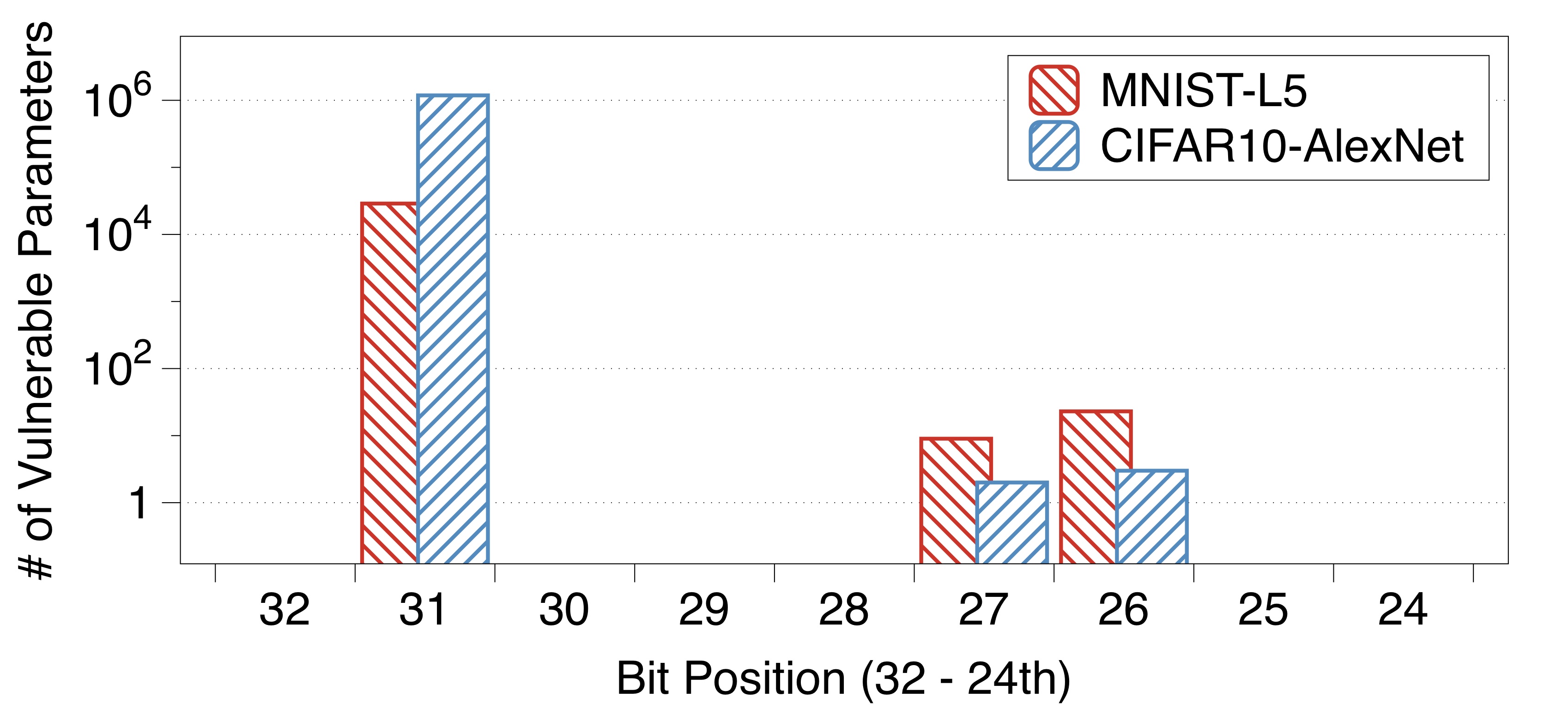
We find that the exponent bits, especially the 31st-bit, lead to indiscriminate damage. The reason is that a bit-flip in the exponents causes to a drastic change of a parameter value, whereas a flip in the mantissa only increases or decreases the value by a small amount—[0,1].
[The impact of the flip direction]:
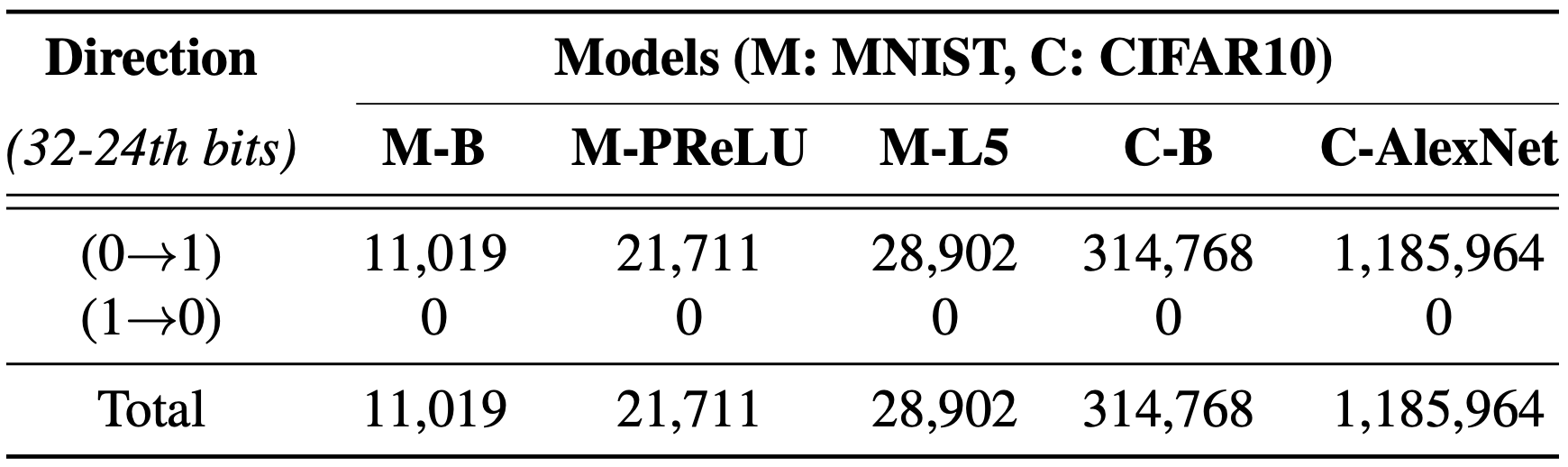
We observe that only (0→1) flips cause indiscriminate damage and no (1→0) flip leads to vulnerability. The reason is that a (1→0) flip can only decrease a parameter’s value, unlike a (0→1) flip. The values of model parameters are usually normally distributed—N(0,1)—that places most of the values within [-1,1] range.
[Impact of the parameter sign]:
We skip the presentation of our analysis details in here. But, our results suggest that positive parameters are more vulnerable to single bit-flips than negative parameters. We identify the common ReLU activation function as the reason: ReLU immediately zeroes out the negative activation values, which are usually caused by the negative parameters. Also, we observe that in the first and last layers, the negative parameters, as well as the positive ones, are vulnerable. We hypothesize that, in the first convolutional layer, changes in the parameters yield a similar effect to corrupting the model inputs directly. On the other hand, in their last layers, DNNs usually have the Softmax function that does not have the same zeroing-out effect as ReLU.
[The impact of the layer width]:
In the table above, in terms of the number of vulnerable parameters, we compare the MNIST-B model with the MNIST-B-Wide model. In the wide model, all the convolutional and fully-connected layers are twice as wide as the corresponding layer in the base model. We see that the ratio of vulnerable parameters is almost the same for both models: 50.2% vs 50.0%. Further, experiments on the CIFAR10-B-Slim and CIFAR10-B—twice as wide as the slim model—produce consistent results: 46.7% and 46.8%. We conclude that the number of vulnerable parameters grows proportionally with the DNN’s width and, as a result, the ratio of vulnerable parameters remains constant at around 50%.
[The impact of the activation function]:
Next, we explore whether the choice of activation function affects the vulnerability. We experiment on different activation functions that allow negative outputs, e.g., PReLU, LeakyReLU, or RReLU. These ReLU variants have been shown to improve the training performance and the accuracy of a DNN. We train the MNIST-B-PReLU model; which is exactly the same as the MNIST-B model, except that it replaces ReLU with PReLU. In the above table, we observe that using PReLU causes the negative parameters to become vulnerable and, as a result, leads to a DNN approximately twice as vulnerable as the one that uses ReLU—50.2% vs. 99.2% vulnerable parameters.
[The impact of dropout and batch norm]:
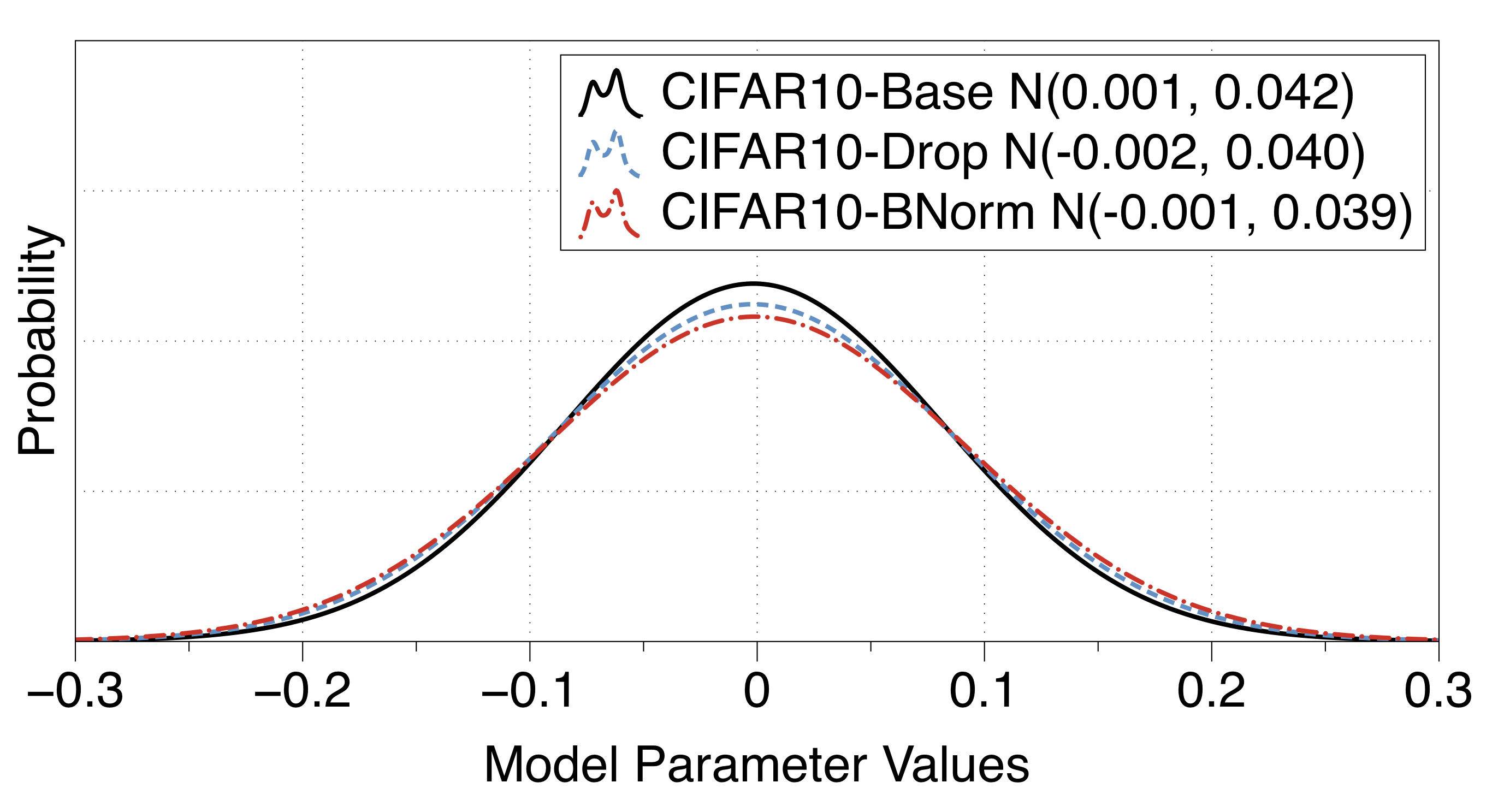
We confirmed that successful bit-flip attacks increase a parameter’s value drastically to cause indiscriminate damage. In consequence, we hypothesize that common techniques that tend to constrain the model parameter values to improve the performance, e.g., dropout or batch normalization, would result in a model more resilient to single bit-flips. Besides the base CIFAR10 and MNIST models, we train the B-Dropout and B-DNorm models for comparison. In the above figure, we compare our three CIFAR10 models and show how dropout and batch-norm have the effect of reducing the parameter values. However, when we look into the vulnerability of these models in our analysis table, we surprisingly find that the vulnerability is mostly persistent regardless of dropout or batch normalization—with at most 6.3% reduction in vulnerable parameter ratio over the base network.
[The impact of the model architecture]:
In the table of 19 DNN analysis results, we showed that vulnerable parameter ratio is mostly consistent across different DNN architectures. However, we see that the InceptionV3 model for ImageNet has a relatively lower ratio—40.8%—compared to the other models—between 42.1% and 48.9%. We hypothesize that the reason is the auxiliary classifiers in the InceptionV3 architecture that have no function at test-time. Interestingly, we also observe that the parameters in batch normalization layers are resilient to a bit-flip: corrupting running_mean and running_var cause negligible damage. In consequence, excluding the parameters in InceptionV3’s multiple batch normalization layers leads to a slight increase in vulnerability—by 0.02%.
Exploit this Vulnerability with Rowhammer
[Threat Model]:
We consider a class of modifications that an adversary, using
hardware fault attacks, can induce in practice. We assume a cloud
environment where the victim’s deep learning system is deployed
inside a VM—or a container—to serve the requests of external users.
For making test-time inferences, the trained DNN model and its
parameters are loaded into the system’s (shared) memory and
remain constant in normal operation. Recent studies describe this
as a typical scenario in Machihne-Learning-as-a-Service (MLaaS).
- [Capability]: We consider an attacker co-located in the same physical host machine as the victim’s deep learning system. We take into account two possible scenarios: 1) a surgical attack scenario where the attacker can cause a bit-flip at an intended location in the victim’s process memory by leveraging advanced memory massaging primitives to obtain more precise results; and 2) a blind attack where the attacker lacks fine-grained control over the bit-flips; thus, is completely unaware of where a bit-flip lands in the layout of the model.
- [Knowledge]: We consider two levels for the attacker’s knowledge of the victim model, e.g., the model’s architecture and its parameters as well as their placement in memory: 1) a black-box setting where the attacker has no knowledge of the victim model; and 2) a white-box setting where the attacker knows the victim model, at least partially.
[Hammertime Database] For our analysis, we constructed a simulated environment relying on a database of the Rowhammer vulnerability in 12 DRAM chips, provided by Tatar et al. Different memory chips have a different degree of susceptibility to the Rowhammer vulnerability, enabling us to study the impact of Rowhammer attacks on DNNs in different real-world scenarios. We perform our analysis on an exemplary deep learning application implemented in PyTorch, constantly querying an ImageNet model. We use ImageNet models since we focus on a scenario where the victim has a relevant memory footprint that can be realistically be targeted by hardware fault attacks such as Rowhammer in practical settings.
Due to this large attack surface, we identified that a Rowhammer-enabled attacker armed with knowledge of the network’s parameters and powerful memory massaging primitives can carry out precise and effective indiscriminate attacks in a matter of, at most, few minutes in our simulated environment.
Our surgical attacker has the capability of causing a bit-flip at the specific location in memory. The two surgical attackers are available: the attacker with the knowledge of the victim model (white-box) and without (black-box). However, here, we assume that the strongest attacker knows the parameters to compromise and is capable of triggering bit-flips on its corresponding memory location. Then, this attacker can take advantage of accurate memory massing primitives (e.g., memory deduplication) to achieve 100% attack success rate.
[Memory templating]: Since a surgical attacker knows the location of vulnerable parameters, she can template the memory up front. That is, the attacker scans the memory by inducing Rowhammer bit-flips in her own allocated chunks and looking for exploitable bit-flips. A surgical attacker aims at specific bit-flips. Hence, while templating the memory, the attacker simplifies the scan by looking for bit-flips located at specific offsets from the start address of a memory page (i.e., 4 KB)—the smallest possible chunk allocated from the OS. This allows the attacker to find memory pages vulnerable to Rowhammer bit-flips at a given page offset (i.e., vulnerable templates), which they can later use to predictably attack the victim data stored at that location.
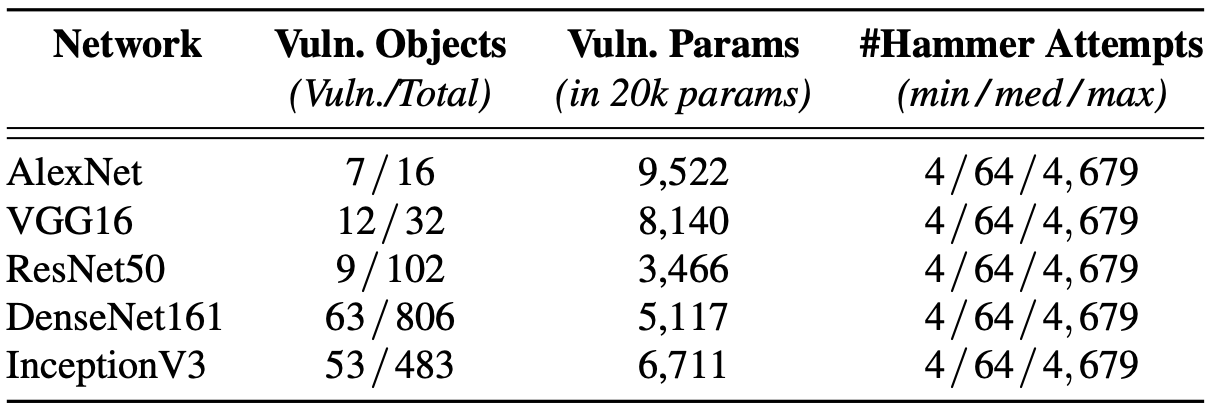
[Vulnerable templates]: To locate the parameters of the attacker’s interest within the memory page, she needs to find page-aligned data in the victim model. Modern memory allocators improve performances by storing large objects (usually multiples of the page size) page-aligned whereas smaller objects are not. Thus, we first analyze the allocations performed by the PyTorch framework running on Python to understand if it performs such optimized page-aligned allocations for large objects similar to other programs. We discovered this to be the case for all the objects larger than 1 MB—i.e., our attacker needs to target the parameters such as weight, bias, and so on, stored as tensor objects in layers, larger than 1 MB. Then, again focusing on the ImageNet models, we analyzed them to identify the objects that satisfy this condition. Even if the ratio between the total number of objects and target objects may seem often unbalanced in favor of the small ones, we found that the number of vulnerable parameters in the target objects is still significant (see Table 4). Furthermore, it is important to note that when considering a surgical attacker, she only needs one single vulnerable template to compromise the victim model, and there is only 1,024 possible offsets where we can store a 4-byte parameter within a 4 KB page.
Due to a DNN model's large attack surface and the resiliency to spurious bit-flips of the (perhaps idle) code regions, allowed us to build successful blind attacks against the ImageNet-VGG16 model and inflict “terminal brain damage” even when the model is hidden from the attacker in our simulated environment.
Our blind attacker cannot control the bit-flips caused by Rowhammer. As a result, the attacker may corrupt bits in the DNN’s parameters as well as the code blocks in the victim process’s memory. In practice, even an attacker with limited knowledge of the system memory allocator, can heavily influence the physical memory layout by means of specially crafted memory allocations. Since this strategy allows attackers to achieve co-location with the victim memory and avoid unnecessary fault propagation in practical settings, we restrict our analysis to a scenario where bit-flips can only (blindly) corrupt memory of the victim deep learning process.
[Methods]:
With the ImageNet-VGG16 model, we run our PyTorch application
under the pressure of Rowhammer bit-flips indiscriminately
targeting both code and data regions of the process’s memory.
Our goal is twofold:
1) to understand the effectiveness of such attack vector
in a less controlled environment and
2) to examine the robustness of a running DNN application
to Rowhammer bit-flips by measuring the number of failures
(i.e., crashes)
that our blind attacker may inadvertently induce.
For every one of the 12 vulnerable DRAM setups available in
the database, we carried out 25 experiments where we
performed at most 300 “hammering” attempts—value chosen
after the surgical attack analysis where a median of 64
attempts was required. The experiment has three possible
outcomes:
1) we trigger one(or more) effective bit-flip(s) that
compromise the model, and we record the relative accuracy
drop when performing our testing queries;
2) we trigger one(or more) effective bit-flip(s) in other
victim memory locations that result in a crash of the deep
learning process;
3) we reach the “timeout” value of 300 hammering attempts.
We set such “timeout” value to bound our experimental
analysis which would otherwise result too lengthy.
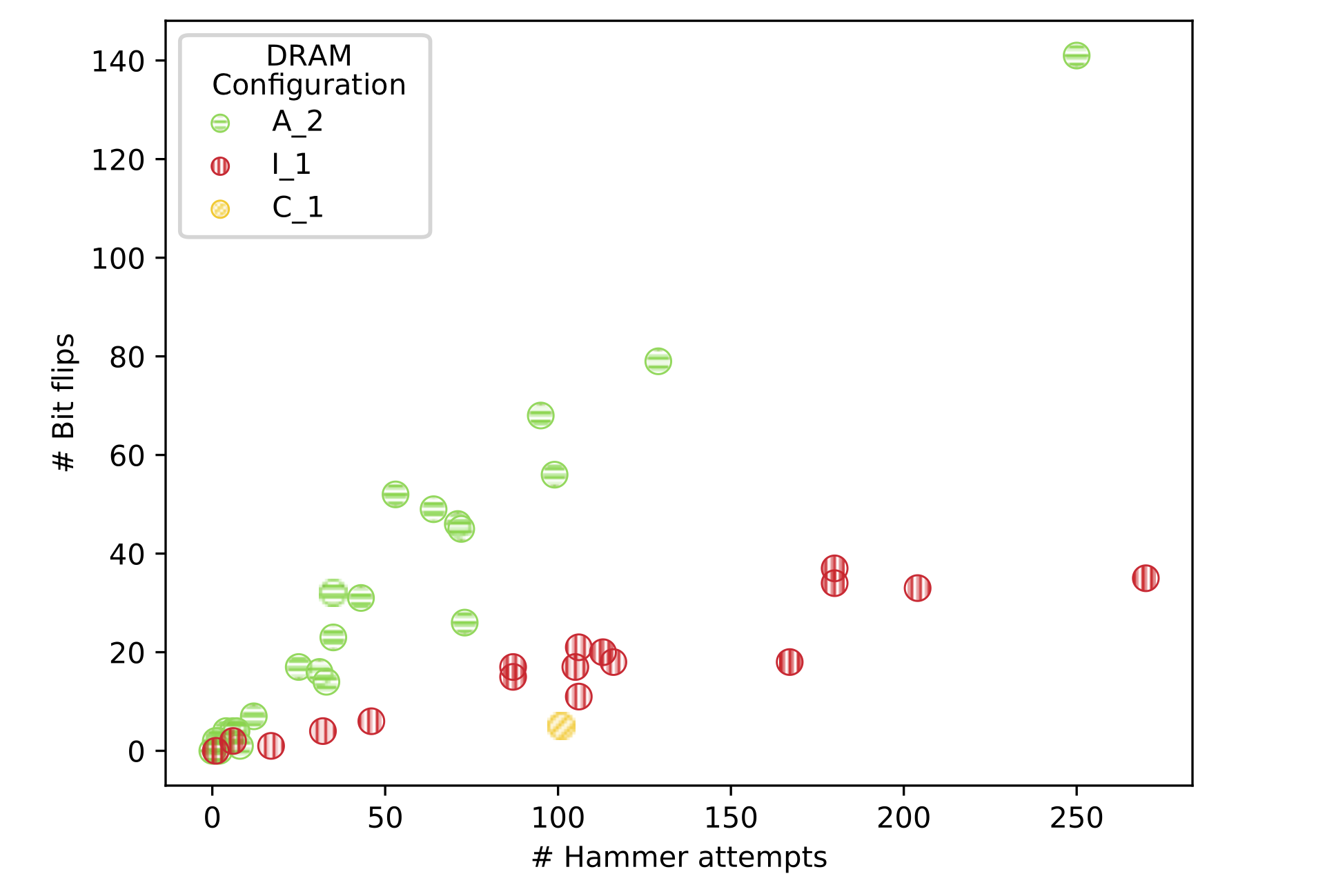
[Results]: In the above figure, we present the results for three sampled DRAM setups. We picked A_2, I_1, and C_1 as representative samples since they are the most, least, and moderately vulnerable DRAM chips. We found A_2 obtains successful indiscriminate damages to the model in 24 out of 25 experiments while, in less vulnerable environments such as C_1, the number of successes decreases to only one while the other 24 times out. However, it is important to note that a timeout does not represent a negative result—a crash. Contrarily, C_1 only had a single successful attack.
DNN-level Mechanisms for Mitigation
We discuss and evaluate potential mitigation mechanisms to protect against single-bit attacks on DNNs. We discuss two research directions towards making DNN models resilient to bit-flips: restricting activation magnitudes and using low-precision numbers. Prior work on defenses against Rowhammer attacks suggests system-level defenses that often even require specific hardware support. Yet they have not been widely deployed since they require infrastructure-wide changes from cloud host providers. Moreover, even though the infrastructure is resilient to Rowhammer attacks, an adversary can leverage other vectors to exploit bit-flip attacks for corrupting a model. Thus, we focus on the solutions that can be directly implemented on the defended DNN model.
We hypothesize that
an activation function, which produces its output
in a constrained range, would make indiscriminate damage
harder to induce via bit-flips.
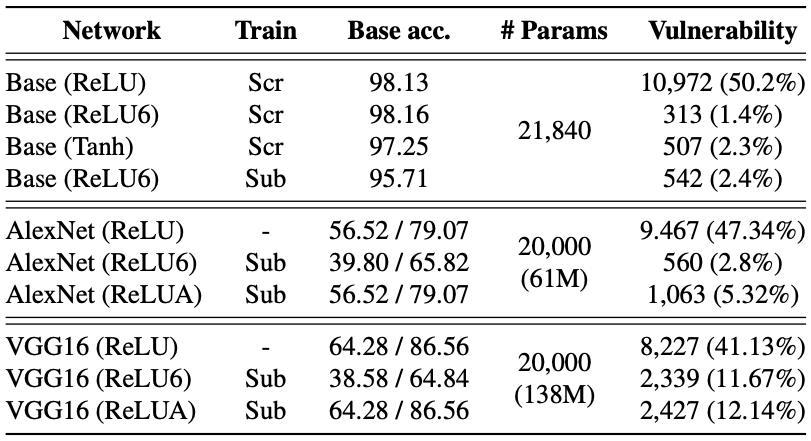
The above table shows the effectiveness of our defensive
mechanism. In the MNIST models, we observe that the ratio of
vulnerable parameters drops to 1.4-2.4% from 50%; without
incurring any significant performance loss. Also, we
discover that the substitution with ReLU6 achieves a similar
effect without re-training; however, it fails to prevent the
vulnerability in the last layer, which uses Softmax instead
of ReLU. In AlexNet and VGG16, we also observe a decrease
in the ratio of vulnerable parameters—47.34% to 2.8% and
41.13% to 11.67%—; however, with significant loss of accuracy.
To minimize the loss, we set the range of activation in
AlexNet (ReLUA) and VGG16 (ReLUA) by selecting the maximum
activation value in each layer. We see that ReLUA leads to
a trade-off between the ratio of vulnerable parameters and
the accuracy.
Takeaways. We showed that this mechanism
1) allows a defender to control the trade-off between the
RAD and reducing the vulnerable parameters and 2) enables
ad-hoc defenses to DNN models, which does not require
training the network from scratch. However, the remaining
number of vulnerable parameters shows that the Rowhammer
attacker still could inflict damage, with a reduced success
rate.
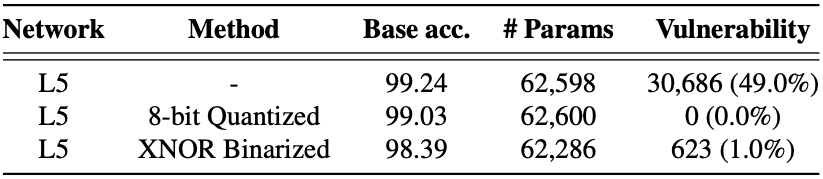
We hypothesize that
the use of low-precision numbers would make a
parameter more resilient to such changes.
For example, an integer expressed as the 8-bit quantized
format can be increased at most 128 by a flip in the most
significant bit—8th bit.
The above table shows the effectiveness of using
low-precision parameters. We find that using low-precision
parameters reduces the vulnerability: in all cases, the
ratio of vulnerable parameters drops from 49% (Baseline) to
0-2% (surprisingly 0% with the quantization). We also
observe that, in the binarized model, the first convolutional
and the last classification layers contain most of the
vulnerable parameters; with 150 and 420 vulnerable
parameters, respectively. This also corroborates with our
results in the characterizations.
Takeaways. Even though 8-bit quantization
mitigates the vulnerability, in a real-world scenario,
training a large model, from scratch can take a week on a
supercomputing cluster. This computational burden lessens
the practicality of this defensive mechanism.
Acknowledgements
We thank Dr. Tom Goldstein, Dana Dachman-Soled, our shepherd, David Evans, and the anonymous reviewers for their feedback. We also acknowledge the University of Maryland super-computing resources (DeepThought2) made available for conducting the experiments reported in our paper. This research was partially supported by the Department of Defense, by the United States Office of Naval Research (ONR) under contract N00014-17-1-2782 (BinRec), by the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 786669 (ReAct) and No. 825377 (UNICORE), and by the Netherlands Organisation for Scientific Research through grant NWO 639.021.753 VENI (PantaRhei). This paper reflects only the authors’ view. The funding agencies are not responsible for any use that may be made of the information it contains.