Philip Resnik's research in computational political science
Note: This page needs an update. The work described here may not be current, but it does provide a good sense of my research approach and may therefore still be useful.
Computational political science is emerging as an incredibly
interesting research area, one that shares the momentum that's
building in computational
social science more generally. I've been finding myself involved
in a number of public conversations about this
topic, and in my work I've been focusing on the following:
Outside the academic context, I'm also an advisor to Converseon, a leading social media consultancy,
and I was founder of React Labs, which commercialized my work on mobile real-time response technology.
For more information about me or my research, see my home page.
Syntactic Framing
One of my very favorite linguistic examples:
when he was about four years old, why did my son say "My toy broke"
instead of "I broke my toy"? He was using syntax to package up the
statement about what happened in a way that de-emphasizes semantic
properties such as causation, volition, and change-of-state. This is
an example of using syntax to frame the issue, an example of "spin"
no different from what Ronald
Reagan did in 1987 when he sidestepped attributing responsibility for
the Iran-contra scandal; remember "Mistakes were made"? (Precocious
child.)
My student Stephan
Greene
did a
fascinating dissertation on this topic, and for a
conference-paper-length description see
our 2009
NAACL paper. Some more recent work includes replicating some of his basic results in Arabic in collaboration with Aya Zirikly.
React Labs: real-time polling
One of the big challenges facing data-driven work in political science
is gathering good data. Analyzing Twitter
is all well and good, but it has significant disadvantages, too. What
you'd really like is something that combines the control you get in
focus groups or polls (particularly the ability to focus on particular
questions) with the large-scale, instantaneous reactions of social
media populations.
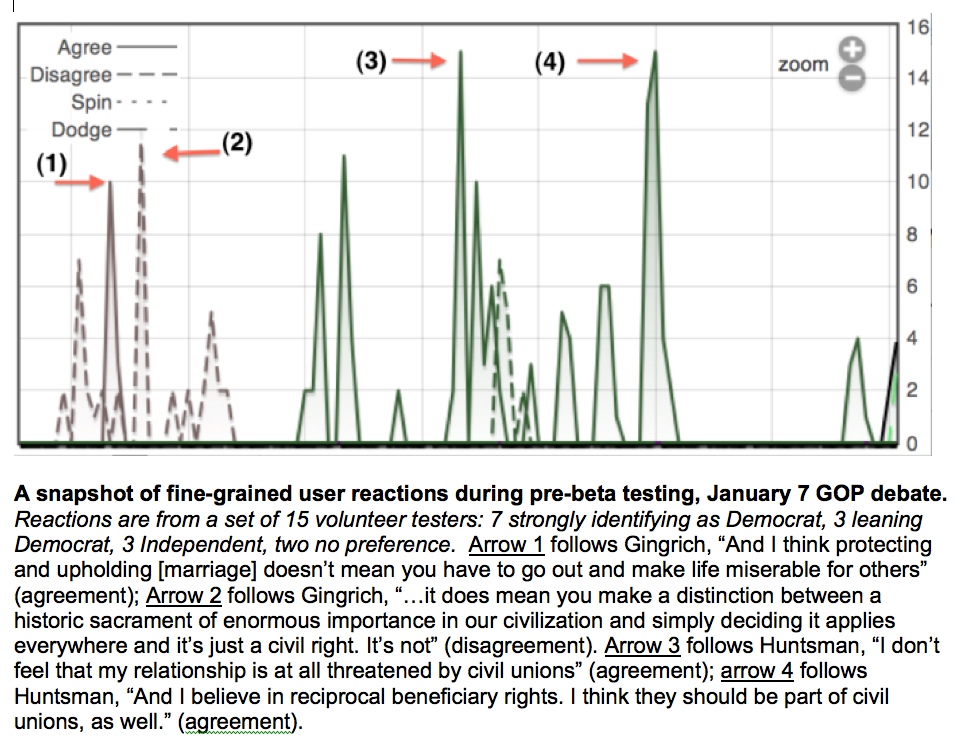
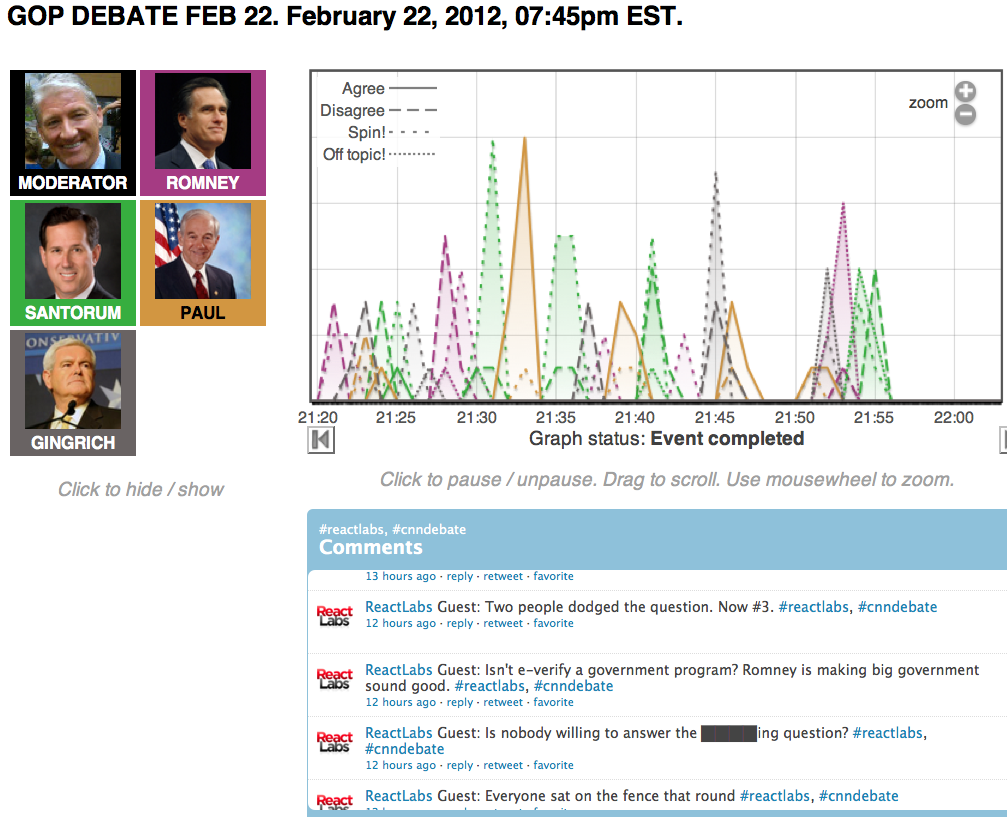
I started the React Labs project to create just that.
The project developed an app that lets people watch live events like political debates and
speeches and react to them using their smartphones or other mobile devices in real
time. During the event, live charting is updated second by second to
provide a dynamic picture of people's reactions, and it's also possible to push survey questions to them dynamically. The ambition is
essentially to put a more sophisticated kind of
Nielsen dial in the
hands of every smartphone user in the country. It can also
be used in more controlled settings -- for example, enabling the
audience to provide real-time feedback to a speaker. A journal article about the project appeared in the Spring 2014 issue of Public Opinion Quarterly.
I am working with folks at the Maryland Technology Enterprise
Institute on commercializing this technology. The platform debuted commercially in a partership with
ABC7/WJLA-DC during the 2012 Obama-Romney debates and, in the process, helped
a team comprising NewsChannel8, Politico, and ABC7/WJLA-TV,
win a 2013 Walter Cronkite Award for Excellence in Television Political Journalism for their election coverage
(see this announcement).
Computational modeling of sentiment, perspective, and framing
In their important 2008 book
on the topic, Bo Pang and Lillian Lee pointed out that there
was a "land rush" starting in the area of sentiment analysis.
Today it's easy to find companies tracking sentiment about
brands and products in social media for business
purposes. The
political world has caught on, as well, with lots of people tracking
mentions of political candidates and some even suggesting
that automatic analysis of opinions on Twitter could be better
than traditional polling. I have talked about the use of
sentiment analysis in political contexts, and some of the issues and hype
surrounding it, in some recent (and by now also not-so-recent) public
discussions.
In my current academic research, I'm less focused on straight
positive-versus-negative sentiment analysis (though sentiment analysis
for other
languages remains a topic of interest). What's really got me excited
is the idea of applying the same sorts of computational ideas to
the related topic of framing -- that is, the way that language can be used
to emphasize or de-emphasize different aspects of a topic or issue, often in service
of a particular agenda or ideological perspective.
(When this is done deliberately in political discourse,
particularly by someone we disagree with, we often call it spin.)
Until pretty recently, framing was a subject that had received relatively little attention from a computational perspective.
As an example of some relatively early work,
my student Stephan Greene did a nice dissertation laying the foundations for a linguistically well founded approach to framing, focusing on the way that grammatical choices encourage particular interpretations, which we summarized in a 2009 paper. (When my youngest son says "Daddy, my toy broke" to de-emphasize his own role in what happened, he's exploiting the same linguistic strategy Ronald Reagan did when he famously said "Mistakes were made". Notice that this isn't just about passive voice; he is exercising the causative/inchoative alternation, not the active/passive distinction.)
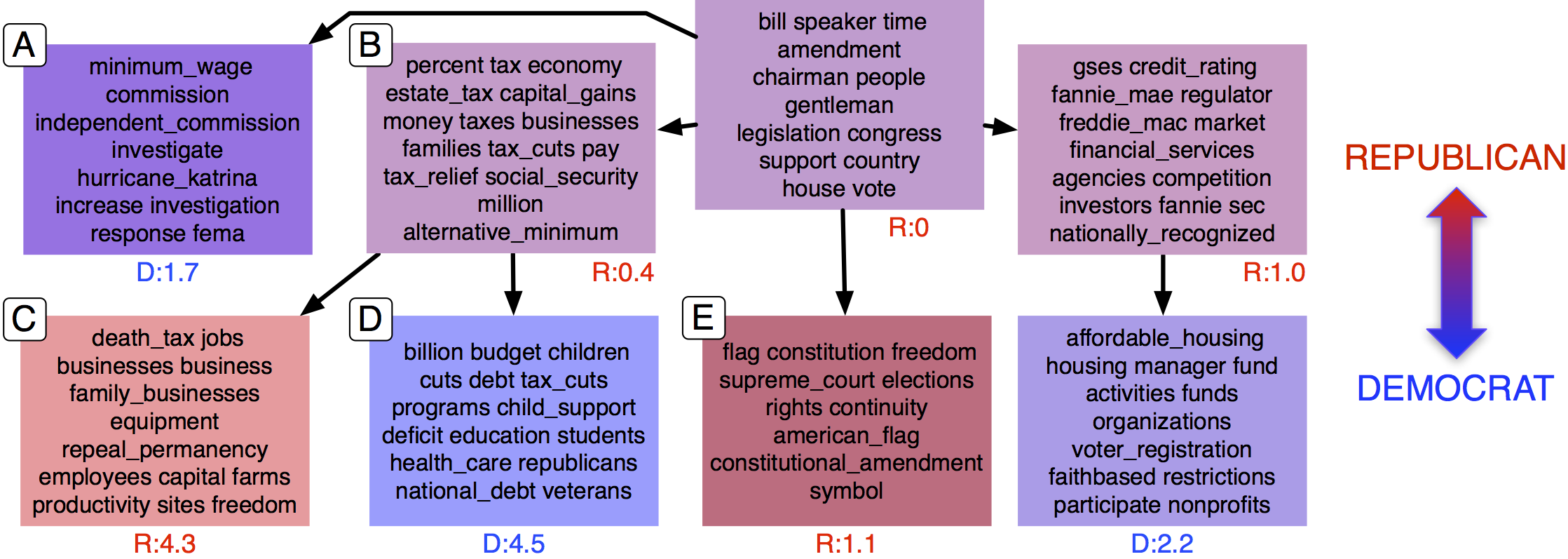
In more recent work, colleagues and I have been developing computational models of this syntactic framing phenomenon, as well as lexical framing (e.g. the choice of whether to say death tax or estate tax), and hierarchical models for framing that are inspired by theories of framing as second level agenda-setting. For example, in the figure above, a hierarchical supervised analysis of Congressional floor debates has automatically identified agenda issues including taxation (B), and it distinguishes the Republican-oriented framing of taxation in terms of business interests (C) from the Democratic framing in terms of the programs that taxation supports (children, education, health care veterans, etc. Colleagues and I have also recently looked at intra-Republican framing in
Viet-An Nguyen, Jordan Boyd-Graber, Philip Resnik, and Kristin Miler, Tea Party in the House: A Hierarchical Ideal Point Topic Model and Its Application to Republican Legislators in the 112th Congress" (Association for Computational Linguistics Conference, Beijing, July, 2015).
Here are links to some other recent publications on
supervised hierarchical topic models of agenda-setting and framing,
political ideology detection using recursive neural networks,
learning concept hierarchies from multi-labeled documents,
identifying media frames and frame dynamics within and across policy issues.
Computational modeling of influence
Who has control of the agenda in a political conversation, and what do
they do with it? Clearly if someone has the role of moderator, they
exercise some control over what gets talked about. But how strong is
that control? And can we detect and measure objectively when somebody
takes control over the agenda in a conversation?
Jordan
Boyd-Graber, grad student Viet-An Nguyen, and I have developed computational models that analyze a conversation like
a political debate or an episode of Crossfire, and automatically identify both the
topics under discussion and the degree of topic
control that participants are exercising.
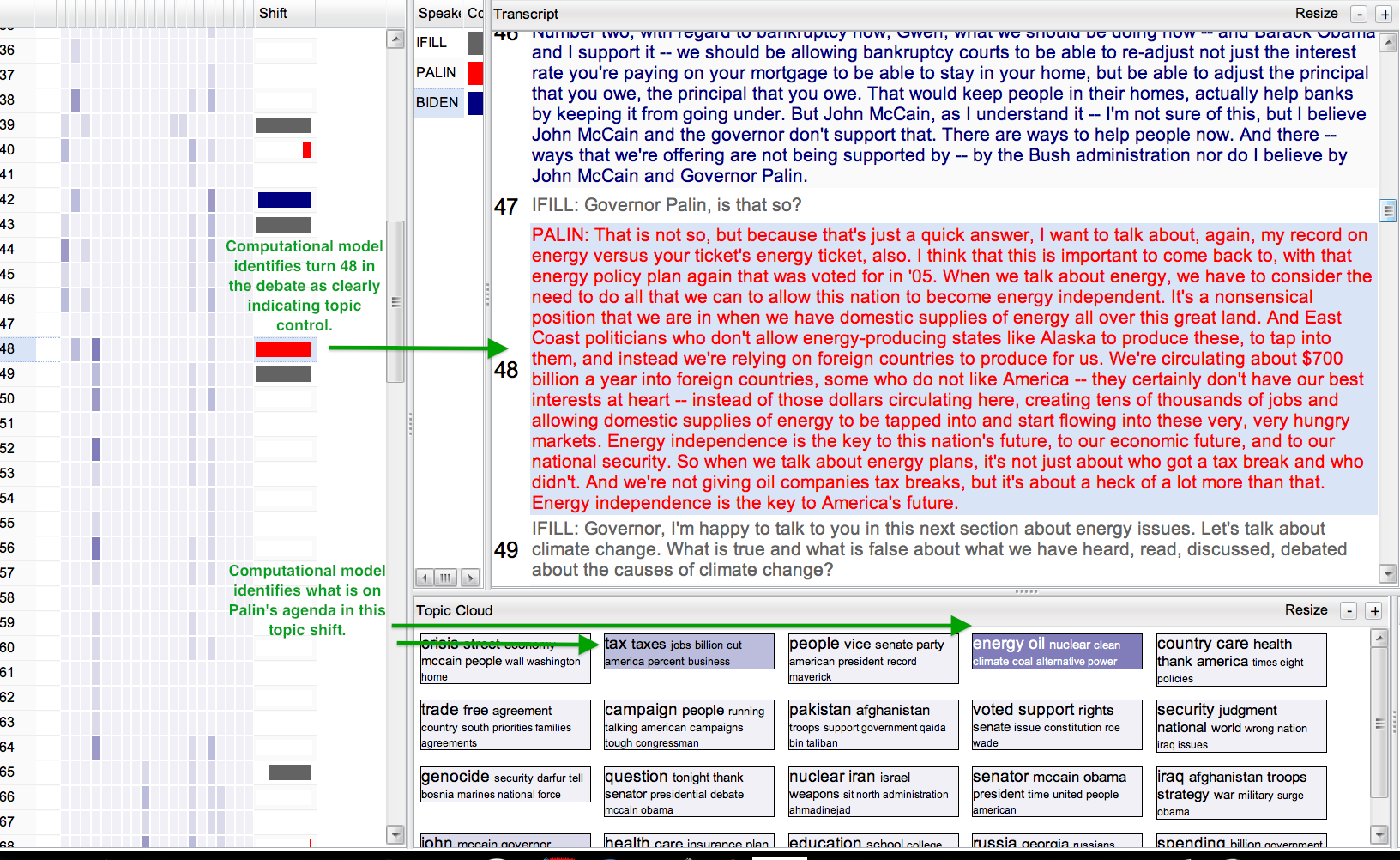
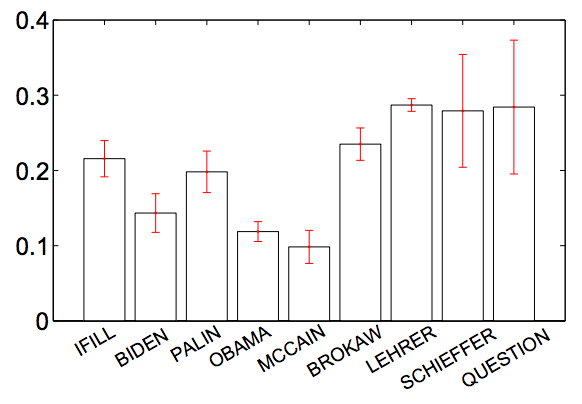
As an example, the automatic analysis of the Biden-Palin debate in
2008 identifies that Gwen Ifill, the moderator, was the person controlling
the topic most of the time (long gray bars in the "Shift" column), but
it also automatically uncovers situations like turn 48 of in debate
transcript, where Palin responded to a question about the mortgage crisis by
talking about energy policy. (This is a particularly clean example, but you'll
certainly find that Biden did the same sort of thing, too!)
Interestingly, if you look at the degree of topic control by all participants in the four 2008 presidential debates,
you find that Palin had the strongest propensity among all the candidates to exert control over the topic being discussed,
and you also find objective empirical support for the widespread perception that Ifill was a weak moderator. (Compare Biden and Palin to Ifill, below, then compare McCain and Obama to their moderators.)
Conversations about computational social science
- March 14, 2015 I organized a SXSW Interactive panel entitled "Are You In a Social Media Experiment?", in which I and other academic and industry experts on social media analysis and experimentation talked about the issues from technological (what’s possible?), policy (what’s appropriate?), and commercial (what’s it good for?) perspectives.
- November 12, 2014 Just days after a hackathon that I helped organize on language analysis for mental health, Newsweek published this nice article on the topic highlighting my perspective along with collaborators Carol Espy-Wilson and (hackathon organizer) Glen Coppersmith.
- October 24, 2014 I spoke at the 2014 Public Opinion Quarterly (POQ) Special Issue Conference on ``Real-Time Reactions to a 2012 Presidential Debate: A Method for Understanding Which Messages Matter''.
- July 29, 2014 I helped out some Wall Street Journal friends in the analysis behind their front-page July 16th story Chief Justice John Roberts has made the Supreme Court the friendliest bar in Washington, which was also picked up in ABA Journal.
- July 15, 2014 I had an interesting conversation on NPR on The Kojo Nnamdi Show's Tech Tuesday, discussing sentiment analysis with Kojo, Kristin Muhlner, CEO of New Brand Analytics, and Kalev (rhymes with 'olive') Leetaru. Fun fact: my Linguistics PhD advisee Stephan Greene is now New Brand's Director of Natural Language Processing.
- June 26, 2014 I was an invited speaker at the excellent ACL Workshop on Language Technologies and Computational Social Science in Baltimore, with a talk entitled ``I Want to Talk About, Again, My Record On Energy...'': Modeling Agendas and Framing in Political Debates and Other Conversations.
- March 8, 2014 I organized and presented at a SXSW Interactive panel entitled Putting a Real-Time Face on Polling, which talked about new methods for tapping into people's thoughts, feelings, and opinions more directly, in real time.
- January 28, 2014 Once again I had a great time appearing on NPR on The Kojo Nnamdi Show, this time with machine learning pioneer Geoffrey Hinton and brilliant Stanford grad student Richard Socher, talking about deep learning.
- January 23, 2013 I was quoted in Feelings, nothing more than feelings: The measured rise of sentiment analysis in journalism", an article from Harvard's Nieman Journalism Lab.
- October 16, 2012 I had a great time appearing on The Kojo Nnamdi Show, co-guesting with Todd Rogers of Harvard's Kennedy School of Government, talking about dodges and spin in political debates, in connection with React Labs, the real-time polling platform that I am currently commercializing.
- October 5-6, 2012. I spoke at the
Harvard
conference on New Directions in Analyzing Text As Data (October
5-6), discussing work with Jordan Boyd-Graber and Viet-An Nguyen in
a talk entitled “‘I Want to Talk About, Again, My Record On
Energy...’: Modeling Control of the Topic in Political Debates and
Other Conversations”.
- August 6, 2012. I appeared on Minnesota Public Radio's "The Daily Circuit" in a discussion about the future of political polling.
- March 24, 2012. I gave a plenary lecture at the 2012
American Association for Applied Linguistics conference,
entitled The
Linguistics of Spin: A Computational Linguist's Forays into Social
Science. The audience used the React Labs app during my talk
(why not talk and beta test at the same time, after all!); a link to results
is at results.reactlabs.org.
- February 11, 2012. I was really pleased to be included
among those quoted in discussions by the Wall Street Journal's
"Numbers Guy", Carl Bialik, about mining Twitter for public opinion,
including both the print
column and the accompanying blog
post.
- January 31, 2012. I had great fun guesting on the Kojo Nnamdi show on
WAMU 88.5 in Washington DC, talking about New
Frontiers in Political Polling: Social Media and "Sentiment
Analysis". We discussed computational analysis of social media
in the context of political campaigns, which was also the topic of the
post I did on Language Log called
#CompuPolitics;
we also briefly discussed the React
Labs project, in which collaborators and I are developing a
smartphone app for large scale, real-time collection of people's
responses during live events like political debates.
- January 17, 2012. My #CompuPolitics posting
on the Language Log linguistics blog
offered a perspective on the hype surrounding social media analysis as the new way
to do political polling.
- November 6, 2011. I gave the keynote talk at
the Sentiment Analysis
Symposium, a regularly held technology/business event focused on sentiment
analysis in social media.
- March 6, 2011 Noah Smith and I gave a presentation on text analysis at South by Southwest Interactive (SXSWi) in March.